
どうも。こんにちは。
ケミカルエンジニアのこーしです。
本日は、「【初級編】非IT系のためのデータサイエンス勉強方法」について解説します。
私自身、化学工学を専門としており、統計学もパソコンも得意ではありませんでした。
しかし、社会人になってから、データサイエンスを勉強し、今では少しずつデータサイエンスを業務で使えるようになっています。
そこで、これからデータサイエンスを勉強したいと考えている初心者の方向けに、体験談を交えてデータサイエンス勉強方法を解説したいと思います。
データサイエンスの「はじめの一歩を踏み出したい」という方は、ぜひ読んでみて下さい!
本記事の内容
・データサイエンスの勉強方法(5つのステップ)
・勉強する目的【超重要!】
・必要な能力とは?
・必要な能力の身につけ方
注意ポイント
本記事は、未経験からデータサイエンティストを目指すことは想定していません。
化学や機械、電気などの技術者が、武器の一つとしてデータサイエンスを身につけるための道しるべと考えています。
この記事を書いた人
 こーし(@mimikousi)
こーし(@mimikousi)
目次
【初心者向け】データサイエンスの勉強方法
データサイエンスの勉強方法を下記の5ステップに分解してみました。
5つのステップ
ステップ1 目的を決める【超重要!!】
ステップ2 必要な能力を知る
ステップ3 ビジネス 力を身につける
ステップ4 データサイエンス 力を身につける
ステップ5 データエンジニアリング 力を身につける
それでは、それぞれのステップについて詳しく解説していきます。
ステップ1 目的を決める【超重要!!】
統計学やPythonの勉強を始めるだけなら簡単です。
今の時代、YouTubeやブログ記事を利用すれば、無料で簡単に勉強を始めることができます。
しかし、データサイエンスの守備範囲は非常に広く、完璧に基礎を固めようと思えば、一生かけても難しいかもしれません。
例えば、勉強すべき内容を列挙してみますと、下記の通りです。
勉強すべき内容
(1)数学
・微分・積分
・線形代数
・確率統計
(2)統計学
・数理統計学
・仮説検定
・実験計画法
・回帰分析
・確率過程
・多変量解析
・時系列分析
・ベイズ統計学
・因果推論
・機械学習
・深層学習
・強化学習
(3)プログラミング
・Python
・R
・SQL
など
軽く列挙しただけでもこれだけあります。
よって、基礎を固めつつも、常に「何がしたいのか」を明確にし、その実現に向けて勉強すべきです。
「何がしたいのか」を具体的にイメージできる状態にしておくことが大事ですね。
参考に、一般的なデータサイエンスの活用例を下記にまとめました。
自分の興味関心、普段の業務から「何がしたいのか」を考えてみてください。
データサイエンス活用例
- 株価の予測:時系列データ解析
- 材料設計:実験計画法
- 画像・音声認識:機械学習、深層学習(ディープラーニング)
- 自然言語処理:深層学習(ディープラーニング)
勉強する目的(具体例)
私が化学プラントで「やりたいこと」を具体例として挙げておきます。
どこまで具体的にイメージできるかによって、挫折するかどうかが決まると思います。
化学プラントにピンとこない方は、ここは読み飛ばしてもらって構いません。
化学プラントにおけるデータ活用イメージ
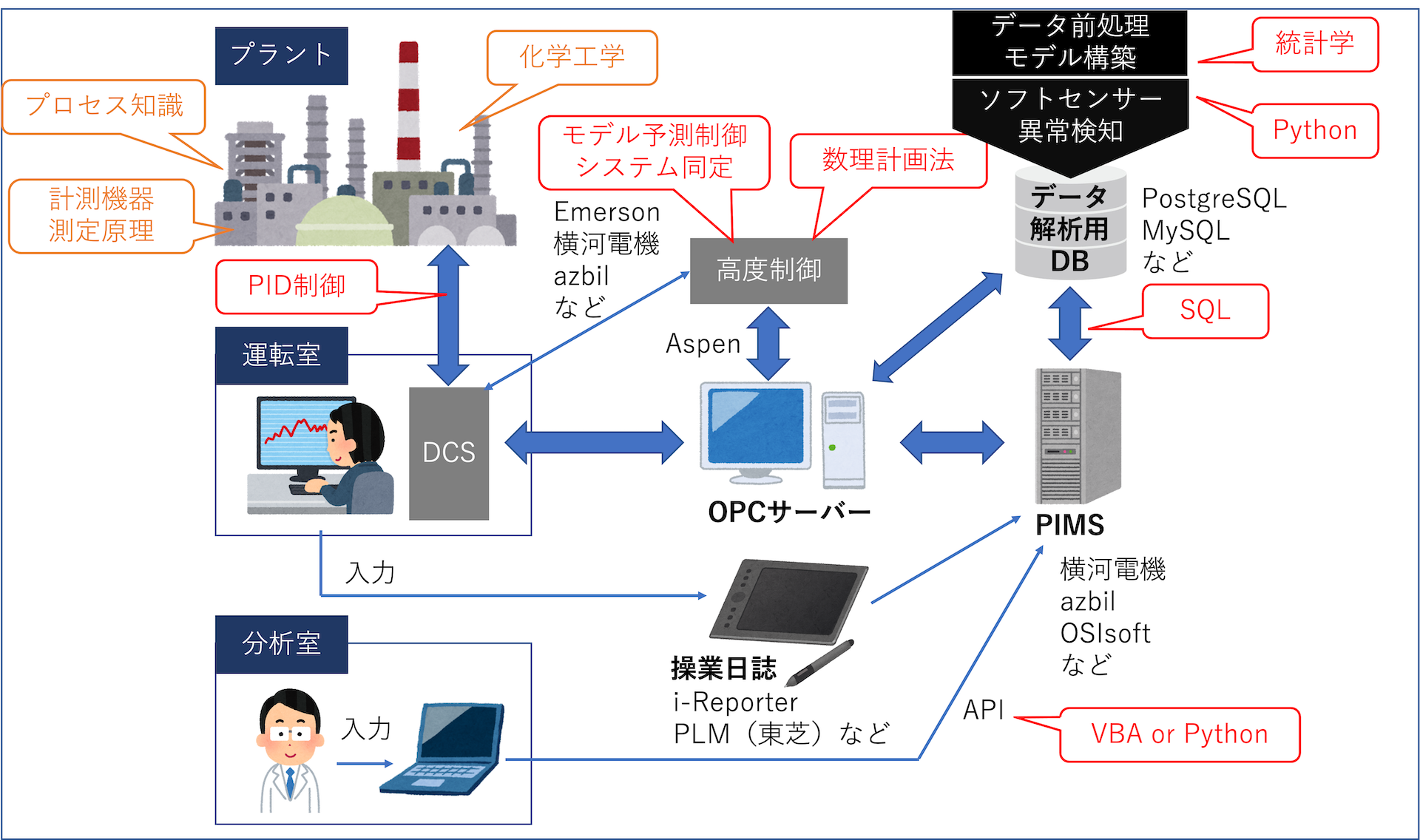
化学プラントでやりたいことは下記6点です。
やりたいこと
①ソフトセンサー
②数理計画法
③異常検知
④モデル予測制御、システム(モデル)同定
⑤製造データの可視化
⑥運転管理ダッシュボード作成
①ソフトセンサー(製品の品質予測)
製品の品質項目のなかには、オンライン分析計で測定できないものが多く、ラボで手分析しています。
そこで、品質の手分析データと製造データ(温度や圧力などの測定データ)から回帰モデルを作成し、品質をリアルタイムで予測したいと考えています。
この技術を「ソフトセンサー」と呼びます。
【参考記事】ソフトセンサー
通常、サンプリングや分析に時間がかかるため、数時間に1点しか取れなかったようなデータが、ソフトセンサーにより連続的に把握できるようになります。
結果、「品種切替の効率化(歩留まりの向上)」や「ムダな運転操作の削減(原単位改善)」が見込めます。
また、手分析データを半自動でデータベースに転送し、常に回帰モデルの補正を行うことも考えています(適応型ソフトセンサー)。
ちなみに、データの転送を半自動にしているのは、再検査や測定ミスを想定しているからです。
上記の内容を実施するためには、最低でも下記3つのシステムを構築する必要があります。
①手分析データをデータベースに転送するシステム
②データベースから演算プログラム(回帰モデルの補正、予測値の演算を行う)への転送システム
③演算した予測値をDCSやPCなどに表示するシステム
データ分析だけでなく、ネットワークやデータベース操作の知識も必要になってきます。
ソフトセンサーが作成できても、実装して運用するまでには、いくつものハードルがあることがわかります。
②数理計画法(運転条件の最適化)
化学プラントは、大きく分けると「反応」と「精製」工程に分離できます。
ざっくりとした書き方になってしまいますが、「反応」を強くすると純粋な製品ができあがり、「精製」の負荷が下がります。
しかし、「反応」を強くすることで、収率が低下したり、溶媒のロスが多くなったり、消費エネルギーが増加したりします。
一方、「反応」を弱くすると、不純物や中間体が増加するため、「精製」の負荷が増加します。
つまり、「反応」と「精製」は、トレードオフの関係にあります。
よって、どこかに最適なポイントがあるはずなんです。
原料単価や原油価格などの様々な制約条件を整理しつつ、原単位が最小になるように「数理計画法」によって運転条件の最適化を行いたいと考えています。
③異常検知
元々、設備の予兆検知は人間の「五感」が頼りでした。
例えば、ベテランのエンジニアが「いつもと音が違う」などと言って、設備の異常を発見してきました。
予兆検知例
- 異音
- 異臭
- 振動
- 熱
その後、「人間が感じ取れるものは機械で測定しよう」ということで、振動計の設置などが進んできましたが、1つの計器だけでは通常の運転操作(ポンプ切替、計器の点検など)と異常時の見極めが難しいという課題がありました。
そこで、機械学習や深層学習を使って、多変数データからパターンを読み取り、異常を検出する技術が開発されてきました。

日本の化学プラントは、築30年以上経過する老朽化設備が多く、これまで起きなかったような故障が次々と起こる可能性があります。
設備投資が限られるなか、お金を掛けずにデータから設備の予兆を検知し、適切に設備保全を行っていきたい考えています。
④モデル予測制御、システム(モデル)同定
データサイエンスというよりは、「制御工学」に該当しますが、システム(モデル)同定では、時系列分析など割と高度な統計学の知識を使います。
数理計画法を駆使して「最適運転条件」が出せたとしても、実際の運転に反映できなければ意味がありません。
多くのプラントでは外気温などの外乱や変数同士の相互干渉などによって、プロセスが乱れやすく、運転制約を超えないよう最適運転条件から外れた運転となっています。
よって、外乱やプロセスの動特性を精度良く表すモデルを作成し、そのモデルを用いた制御(モデル予測制御)を行うことでプラントを安定化させ、最適運転条件を維持したいと考えています。
-

-
モデル予測制御とは?【コスト削減の鍵!?】
続きを見る

⑤製造データの可視化
現状、Excelで製造データや品質データをグラフ化しています。
報告資料を作成するたびに、データを抽出し、イチからグラフを作るため、とても非効率だと感じています。
過去に作ったグラフとフォントやサイズ、レンジが合わなかったりして、また全て一つ一つ修正することもあります。(自分が統一できていないだけですが汗)
そこで、インタラクティブなグラフ(拡大したり、範囲ずらしたり、変数を変更したり、簡単にいじれるグラフ)を作成し、データの可視化を効率化したいと考えています。
BIツールを使えば、ある程度効率化できますが、Pythonを使って平均値や標準偏差を自動で計算させたり、自分好みにカスタマイズしたいですね。
⑥運転管理ダッシュボード
データの可視化からもう一歩進んで、運転管理ダッシュボードを作成したいと考えています。
普段の運転管理にはBIツールの活用もアリだと思いますが、ビジネスのコアの部分については、自らインタラクティブなダッシュボードを作成したいです。
運転管理アイデア
- ソフトセンサー(品質予測)
- 異常検知(設備管理)
- 制御性能(パフォーマンス)管理
- 数理計画法(最適運転条件)
プラントの運転室に上記を表示し、リアルタイムで監視できるダッシュボードを作成したいと考えています。
ステップ2 必要な能力を知る
データサイエンスを勉強する目的が定まったら、次はデータ解析に必要な能力を確認しましょう。
データサイエンティストに求められるスキルについて、データサイエンティスト協会が図解してくれていますので、下図を参考にします。
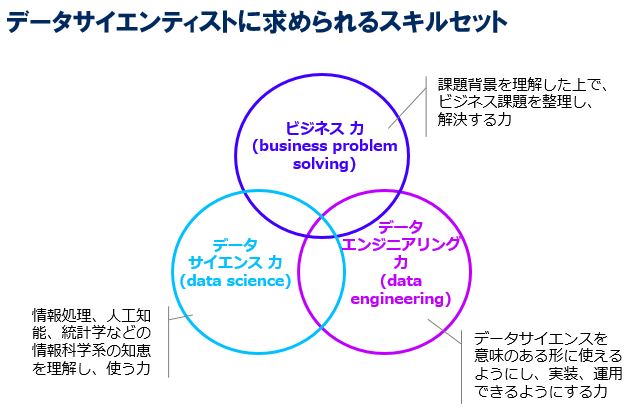
データサイエンティスト協会は、下記3つの力が必要だと述べています。
3つの力
①ビジネス 力
②データサイエンス 力
③データエンジニアリング 力
また、課題解決の各フェーズにおいて、要求されるスキルセットが異なります。
これもデータサイエンティスト協会がわかりやすい図を作成してくれています。

私自身、製造現場にて課題設定⇒データ解析⇒実装⇒効果検証と実際に行ってきましたが、まさに上図のような役割分担となりました。
データ解析の役割分担
課題設定 ⇒ 現場技術者(私)
データ解析 ⇒ データサイエンティスト(社内・社外のエンジニア)
システムの実装 ⇒ システムエンジニア(社内)
効果検証 ⇒ 現場技術者(私)
それでは、それぞれの力について具体的に考えていきます。
①ビジネス 力
最も大事なのは、ビジネス力です。
ビジネス力とは、「ビジネスの課題を整理し、解決する力」のことです。
データサイエンス関係なく、必須の能力ですね。
データサイエンスは課題解決のためのツールのひとつであり、「課題は何か」を教えてくれるものではありません。
データ分析における「課題設定」の方法については、下記の記事で詳しく解説しました。
-
-
【例題でわかる】データ分析の設計方法(課題設定)
続きを見る

また、ビジネス力の根幹となるのは、その分野の専門知識(ドメイン知識)です。
分析対象の専門知識(ドメイン知識)が無いと、データサイエンスも役に立ちません。
これまでデータサイエンティストが何社も営業に来て、データ分析をしてくれましたが、基本的にトンチンカンな結果(外気温による擬相関や因果関係が逆など)を出してくるので、完全に幻滅しました。
「AIには完璧も、完成もない。継続的な改善しかない」
そのため開発プロジェクトは外部に丸投げせず、社内に人材を抱えたり、育てたりする必要がある。
「データサイエンス(AI)で何かやってくれるだろう」という受け身の姿勢ではダメなことがわかりました。
我々は、データサイエンス(AI)を使いこなすことで、ビジネス課題を解決しないといけないのです。
参考記事を紹介しておきます。
【参考記事】幻滅期に突入したAI、個人の技術者がチャンスな理由
②データサイエンス 力
データサイエンス 力とは、情報科学系の知恵を理解し、使う力です。
大きく分けて、下記の学問知識が必要です。
必要な学問
①数学(微分・積分、線形代数、確率統計)
②統計学(統計検定2〜準1級レベル)
③プログラミング(Python,Rなど)
④英語
なんで英語??と思うかもしれませんが、最新技術の情報を得ようとすると、世界共通語の英語で読み書きする必要があります。
日本語に訳されるのは、限られた情報だけであり、しかもだいぶ時間が経った後になります。
また、Pythonライブラリの公式ドキュメントやデータサイエンスの論文など、欲しい情報は英語ばかりになってきます。
とはいえ、初心者は翻訳された情報で十分なので、英語は後回しで大丈夫です。
③データエンジニアリング 力
先ほど、ソフトセンサー実装のところでも記載しましたが、データはきれいに並んで待っている訳ではありません。
欲しいデータを選定、分析、計算したのち、データベースにまとめてやる必要があります。
その際に必要となるのが下記の知識です。(一例です)
必要な知識
①プログラミング(SQL、VBA、Python、Cなど)
②ネットワーク
③データベース
この辺の知識は、IT系のエンジニアに任せることができると思います。
非IT系技術者でも、いずれは勉強すべきですが、初心者は後回しで良いでしょう。
あと、化学プラントでは、何かとDCSに絡めたりするので、DCSの知識もあった方が良いですね。
ステップ3 ビジネス 力を身につける
ビジネス 力を身につける方法を簡単に紹介します。
ビジネス 力を身につける方法
①課題解決に関するビジネス本を読む
②自分の業界の偉人の本を読む
③自分の専門分野の専門書で学ぶ
④あとは実践と改善あるのみ!
①課題解決に関するビジネス本を読む
著名人がおすすめする本を片っ端から読んでみましょう。
特に、課題解決に特化しているコンサルタントが書いた本がオススメです。
例えば、私の場合は下記を読みました。
②自分の業界の偉人の本を読む
業界によって仕事のやり方が異なりますし、自分の業務と近い分野の方が、自分事と捉えることができるのでオススメです。
例えば、私の場合は下記を読みました。
業界の偉人の本
③自分の専門分野の専門書で学ぶ
今の業務に関わる専門書を片っ端から読んでみましょう。
これまでたくさん専門書を読んできましたが、一例を挙げると下記の通りです。
専門書
基本、「化学工学」関連の書籍ですね。
④あとは実践と改善あるのみ!
たくさん本を紹介しましたが、本は「仕事で必要」というモチベーションの高いうちに読むべきですね。(モチベーションコントロールの視点も大事です)
仮に、読んだ本がハズレで役に立たなかったとしても、実践と改善の習慣化(積み重ね)が自分の市場価値を高めてくれるハズです。
ステップ4 データサイエンス 力を身につける
データサイエンス 力を身につける方法を紹介します。
前述の通り、必要な学問は下記の通りです。
必要な学問
①数学(微分・積分、線形代数、確率統計)
②統計学(統計検定2〜準1級レベル)
③プログラミング(Python,Rなど)
④英語
①数学
マセマ出版社のキャンパス・ゼミを読めば、ある程度のレベルまではカバーできます。
数学の基礎を固めるだけでも時間がかかってしまうので、まずは②統計学から勉強しましょう。
いずれ数学のレベルが足りなくなりますので、それから数学を勉強しても遅くないでしょう!
「いつ頃からどのくらい数学を勉強すべきか」については、下記の記事にまとめました。
-
-
【無料あり】統計学のための数学おすすめ参考書
続きを見る

②統計学
数学に比べると、統計学はガッツリ勉強することになります。
統計学の教科書を何冊も読破しないといけません。
初心者向けのおすすめの本は、下記記事にまとめました。
マンガで全体像をつかみ、少しずつ難しい教科書に挑戦する道筋を示しています。
-
-
【初心者向け】統計学のおすすめ本5選(特徴も解説!)
続きを見る

また、基礎固めのために「統計検定」を受験するのもアリだと思います。
「資格試験」という締切とゴールをつくることで、自分に強制力を働かせ勉強を一気に加速させます。
まずは、統計検定2級に挑戦してみましょう!
体験談はこちらの記事にまとめてあります。
-
-
【初心者向け】統計検定2級の難易度は?【合格体験談】
続きを見る

-
-
【失敗しない】統計検定2級のオススメ参考書(無料あり)
続きを見る

ただし、実務で統計学を使うなら、最低「統計検定準1級レベル」は欲しいところですね(できれば1級も狙いたい)。
準1級に合格できる力があれば、ほとんどの機械学習、深層学習の専門書は読みこなせるようになります。
-
-
統計検定準1級(CBT)の難易度を解説!【合格体験談】
続きを見る

-
-
【失敗しない】統計検定準1級向けのおすすめ参考書
続きを見る

基礎固めが終わったら、次は「何がやりたいのか」によって学ぶ内容を決めましょう。
例えば、下記のようなイメージです。
何がやりたいか
・株価を予測したい ⇒ 時系列データ分析
・画像認識がやりたい ⇒ ディープラーニング(深層学習)
・ソフトセンサーを作りたい ⇒ 多変量解析、時系列データ分析
また、多くの人が直面するのは、「統計学」と「プログラミング」のどちらを先に学ぶべきかという問題です。
Googleで検索すると、プログラミングスクールが運営するサイトがヒットし、プログラミングから始めるべきという論調が繰り広げられています。
しかし、結論としては「統計学」が先です。
統計学がわからないのに、PythonやRを使ってデータ解析しても意味のある結果は出ません。
実際の業務でも、統計学を理解してない人が「変な結論」を導き出す例は幾度も見てきました。
統計学を体系的に学ばず、プログラミングスキルに特化した結果、価値のないアウトプットを量産することになります。
一方、統計学さえ理解していれば、PythonやRが使えなくても、Excelを使って業務に活かすことができます。
さらに、データサイエンティストに外注した分析結果の意味が分かりますし、改善指示を出すこともできます。
よって、「統計検定準1級レベル」の統計学の知識を身につけた後、PythonやRを勉強しつつ、並行して統計学の知識を深めていきましょう!
【参考記事】何故データサイエンティストになりたかったら、きちんと体系立てて学ばなければならないのか
③プログラミング
データサイエンスで用いられるプログラミング言語は、Pythonが主流です。
統計解析ソフトのRを使って解説している教科書が多いので、Rを勉強するのもありだと思います(特に医療分野でRが使われている印象)。
しかし、深層学習を使う場合は、ライブラリ(便利なコード集)が豊富なPythonがオススメです。
また、PythonではWebアプリを作成できたり、APIと連携できたりと汎用性が高いのも特徴です。
よって、初心者はまずPythonを勉強すべきです。
【参考記事】PythonとRはどっちを使うべき?
【参考記事】データサイエンティストになるにはRかPythonか【結論:PythonでOK】
【参考記事「データ分析をやるならRとPythonのどちらを使うべき?」への個人的な回答
Pythonの勉強方法は、プログラミング完全初心者であれば、動画講座をオススメします!
プログラミングとはどういうものか、イメージができない状態で、本を読んでも理解が進まないからです。
最近は、YouTubeで無料で見れるものもあります。
もう少し高度な内容であれば、Udemyという動画学習サイトの講座はクオリティが高くて良いですね。
月に1回くらいセール(1200〜1700円くらいになる)をしていますので、その時に購入すると良いと思います。(しかも1ヶ月以内なら返品可能!)
本当にいろんな講座があるので、ぜひUdemyサイト![]() をのぞいて見てください。
をのぞいて見てください。
Pythonの学習方法については、下記に詳しくまとめてます。
-
-
【初心者向け】データサイエンスのためのPython学習方法
続きを見る

④英語
データサイエンスを勉強するだけであれば、「読み」と「聴き」ができれば大丈夫です。
よって、はじめはTOEICを活用して基礎を固めましょう。
-
-
【TOEIC800目指す】理系社会人のためのTOEIC効率的勉強法
続きを見る

基礎を固めたら、あとは英語を実際に使っていきましょう!
統計学の教科書やPython公式ドキュメントを英語で読んだり、YouTubeやUdemyの英語講座を聴講して、データサイエンスを英語で勉強しましょう。
ただし、最初から英語で勉強するのではなく、一度は母国語で勉強した方が理解が早いと思います。
よって、母国語(日本語)で勉強した後に、英語の教材でデータサイエンスを復習するのがオススメです。
ステップ5 データエンジニアリング 力を身につける
非IT系の方が、座学のみでデータエンジニアリング 力を身につけるのは、若干ハードルが高いです。
ビジネス 力とデータサイエンス 力の両方を身につけた後、実務でデータサイエンスを活用してみましょう。
おそらく、すぐにデータエンジニアリング 力の壁にぶち当たるでしょう。
よって、データの取得・整理、解析結果の実装作業については、はじめはITエンジニアに依頼するべきだと思います。
もし、データ解析ができて、PythonやSQLを駆使して自分で実装できるようになったら、一人前の「データサイエンティスト」ですね。
データエンジニアリング 力を身につける方法については中級編の記事で解説したい(準備中)と思います。
まとめ
まとめ
1.まずは「何がしたいのか」勉強する目的を明確にしましょう!(超重要!!)
2.課題を見つけ、データ解析をするためには、ビジネス力 とデータサイエンス 力が必須です。
3.データを収集したり解析結果を実装する際は、データエンジニアリング 力が必要になります。
4.目的を明確にし、要求される3つの力を高めていきましょう!
①ビジネス 力
②データサイエンス 力
③データエンジニアリング 力