
どうも。こんにちは。
ケミカルエンジニアのこーしです。
本日は、「ソフトセンサーの作成方法」についてわかりやすく解説します。
ソフトセンサーが有用であることはわかっているけど、どうやって作成したら良いのかわからないという方が多いと思います。
本記事では、ソフトセンサーの作成方法について体系的に解説しますので、興味のある方はぜひ読んでみてください。
ソフトセンサーとは何か、ソフトセンサーの役割については下の記事にまとめています。
-

-
【図解あり】ソフトセンサーとは 〜コスト削減の武器〜
続きを見る

本記事の内容
・ソフトセンサーの作成方法
・参考文献
この記事を書いた人
 こーし(@mimikousi)
こーし(@mimikousi)
 こーし(
こーし(
ソフトセンサーの作成方法
ソフトセンサー構築の流れを下記にまとめました。
ソフトセンサー構築の流れ
- データ収集
- データの前処理
- モデル構築
- モデル解析
- モデル運用
それでは、一つ一つ具体的に解説していきます。
データ収集
データ収集のポイントは下記2点です。
データ収集のポイント
- 質・信頼性の高いデータを集める
- ソフトセンサーを構築する目的を明確にする
1.質・信頼性の高いデータを集める
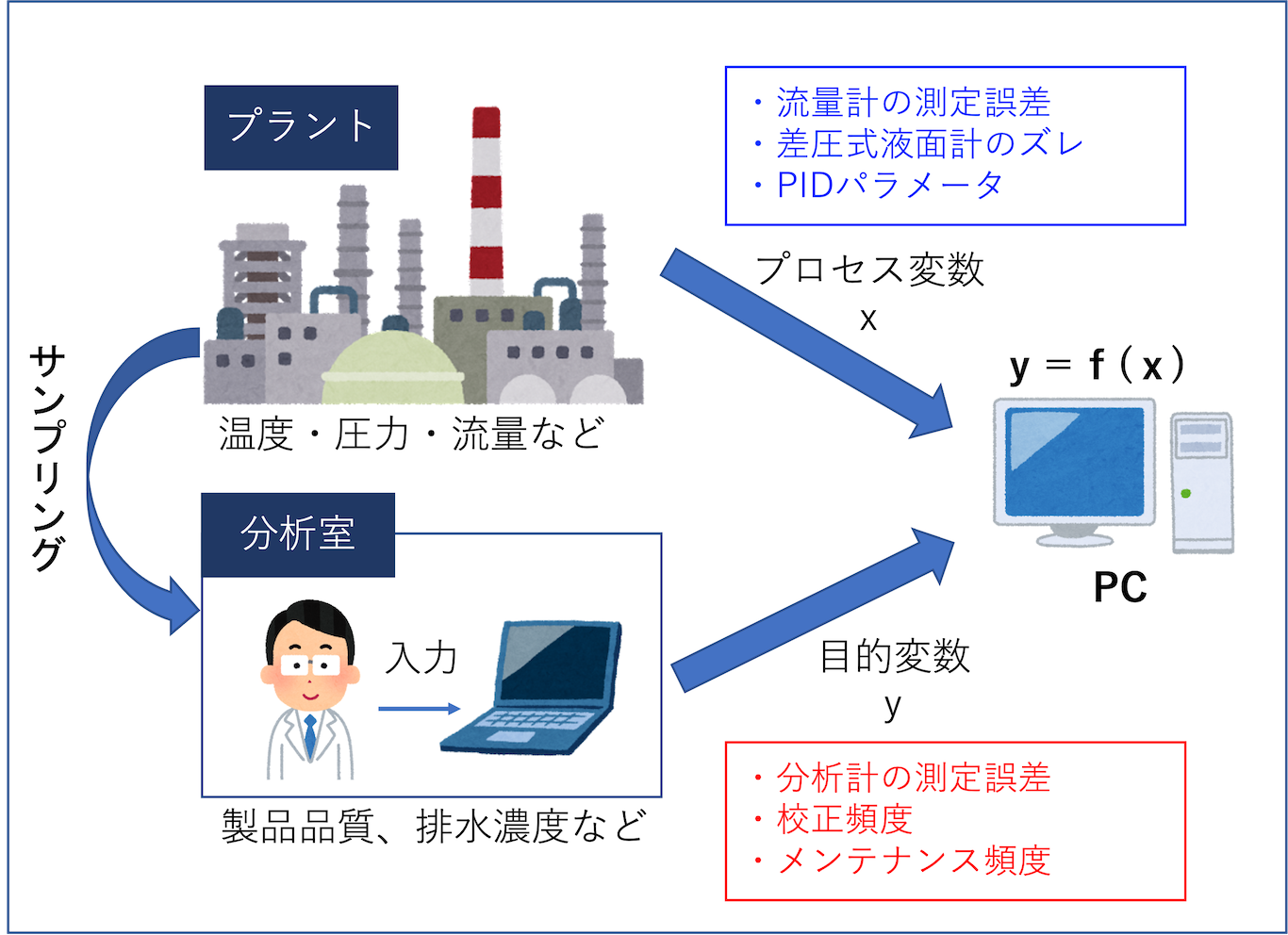
ソフトセンサーを構築するためには、まずデータを集めないといけません。
データが多ければ多いほどソフトセンサーの予測精度は向上します。
しかし、測定ノイズばかりのデータを集めていては精度の高いモデルを構築することは困難です。
よって、質・信頼性の高いデータを集める必要があります。
質・信頼性の高いデータを集めるために、考慮すべきことを下記にまとめました。
考慮すべき点
- 分析計の測定誤差、校正頻度
- 分析計のメンテナンス
- オンライン計器の測定誤差
- PIDパラメータ
化学プラントを例にもう少し具体的に書くと下記の通りです。
化学プラントの例
- 分析計の測定誤差が何%あるか
- 分析計の校正頻度は適切か
- GC、HPLCのカラム交換頻度は適切か
- 流量計の指示値は正確か(例えば、スラリーやエアーは流量誤差が大きい)
- 液面計の指示値は適切か(差圧式の液面計はズレやすい)
- PIDパラメータは適切に設定してあるか
2.ソフトセンサーを構築する目的を明確にする
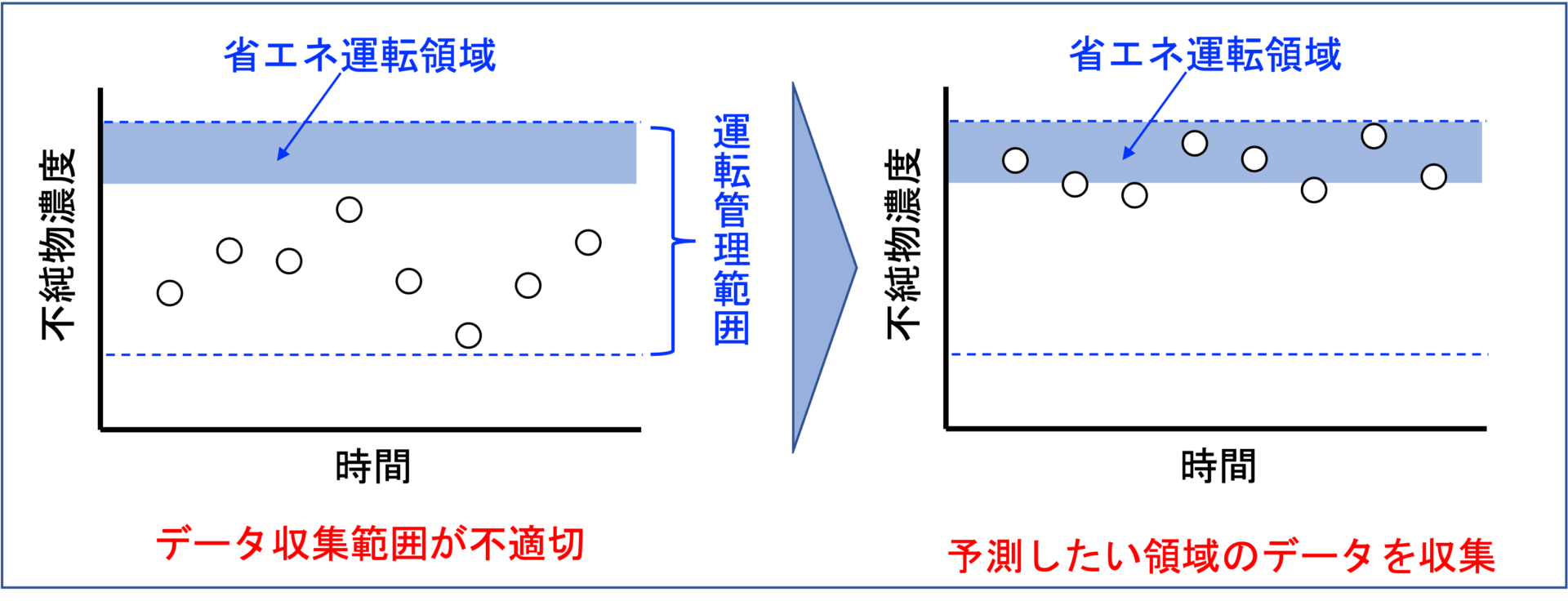
ソフトセンサーを構築する目的によって、追求する予測精度が異なります。
例えば、品質規格ギリギリを攻めた運転管理をしたいという場合、要求する予測精度は高くなります。
一方、分析計の異常を検知したいという目的であればそこまでの予測精度はいらないでしょう。
また、品質規格ギリギリを攻める場合、品質規格近辺で運転した際のデータをたくさん集めてモデルを作成します。
つまり、「予測したい領域」のデータを十分に集めておくことが重要です。
データの前処理
データの前処理は、データ解析作業の8割を占めると言われるほど重要な作業になります。
代表的なデータの前処理を下記にまとめました。
データの前処理
- 外れ値除去
- ノイズ処理(平滑化)
- プロセス動特性の考慮
- 変数選択
- xやyの変数変換
1.外れ値除去
外れ値除去の方法としてはいくつかありますが、ソフトセンサー構築時に用いられる代表的な手法は下記3つです。
①3シグマ法
②Hampel identifier
③SG法による平滑化処理前後の値の差に対してHampel identifier
化学プラントではプロセスが周期的に変動している場合が多く、③が有効な場合が多い印象です。
①3シグマ法や②Hampel identifierについては下記記事でまとめています。
-
-
【エクセルでできる】外れ値の検出方法
続きを見る

-
-
【python】単変量の外れ値除去:3つの手法を比較
続きを見る

2.ノイズ処理(平滑化)
ノイズ処理としては、下記3つがよく使われています。
- 移動平均
- SG法(Savitzky Goley法)
- PCA(主成分分析)
移動平均をとるデータ数やSG法の多項式の次数、近似するデータ幅などのパラメータについては、ノイズの正規性を元に決定します。
詳しくは下記の記事を参考にしてみてください。
スペクトル・時系列データの前処理の方法~平滑化 (スムージング) と微分~
その他、PLSやSVRのようなノイズに頑健な回帰分析手法を用いるという手もありますね。
pythonによる平滑化については下記記事で詳しく解説しています。
-
-
【python】プロセスデータ の平滑化(savgol_filter)
続きを見る

3.プロセス動特性の考慮
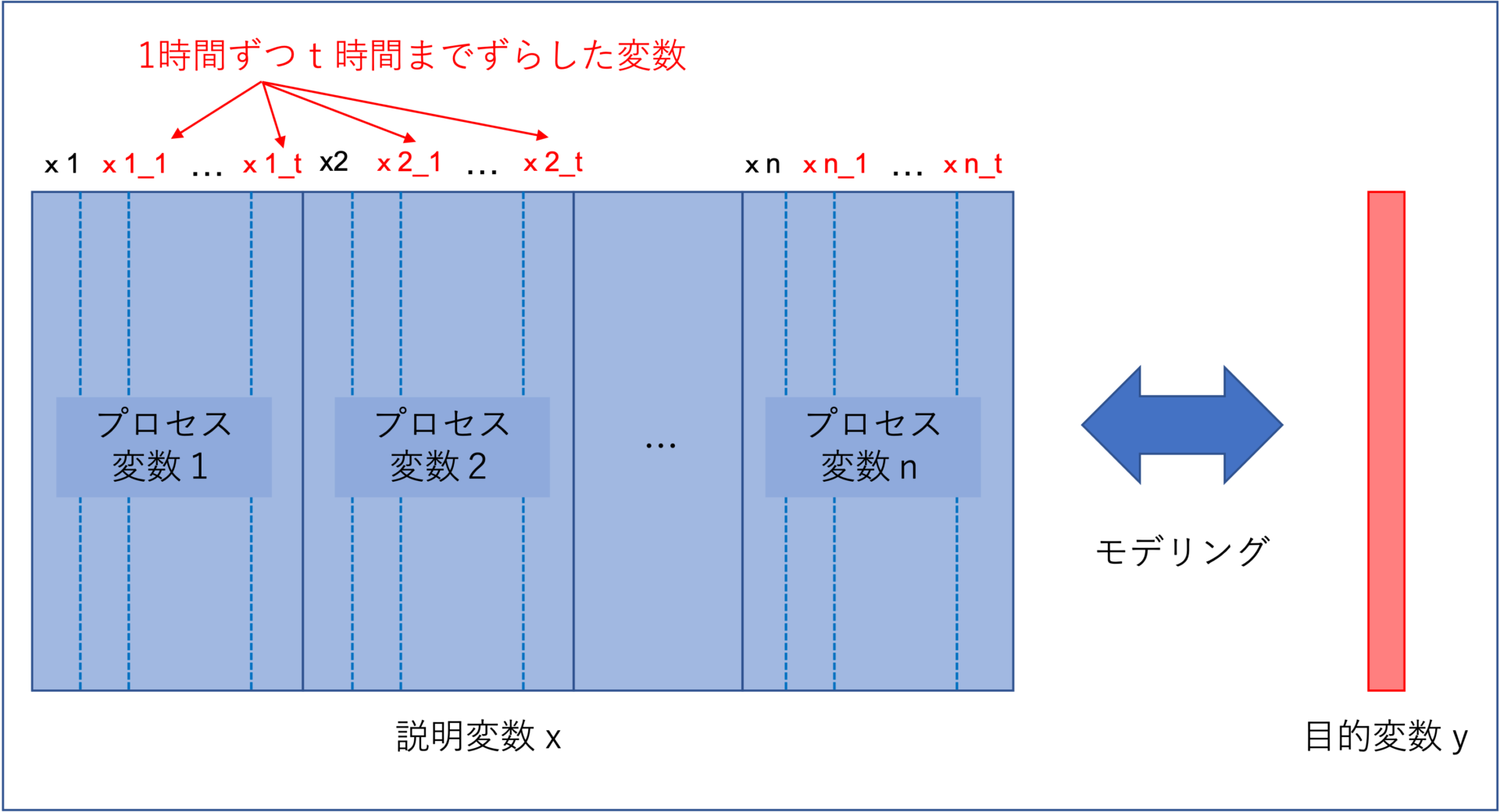
製造プロセスにおいて、各プロセス変数xは時間遅れを伴って目的変数yに影響を及ぼします。
よって、プロセス知識に基づいて、数時間または数分だけ過去の変数をモデル構築に用います。
例えば、目的変数yの前工程にあるプロセス変数(説明変数)であれば、滞留時間分(1時間とか)遅らせた変数をモデルに用います。
しかし、どのくらい時間遅れを考慮したら良いのかはっきりしない場合もあると思います。
その際は、次に説明する「変数選択」を組み合わせて試行錯誤的に時間遅れを決定します。
4.変数選択
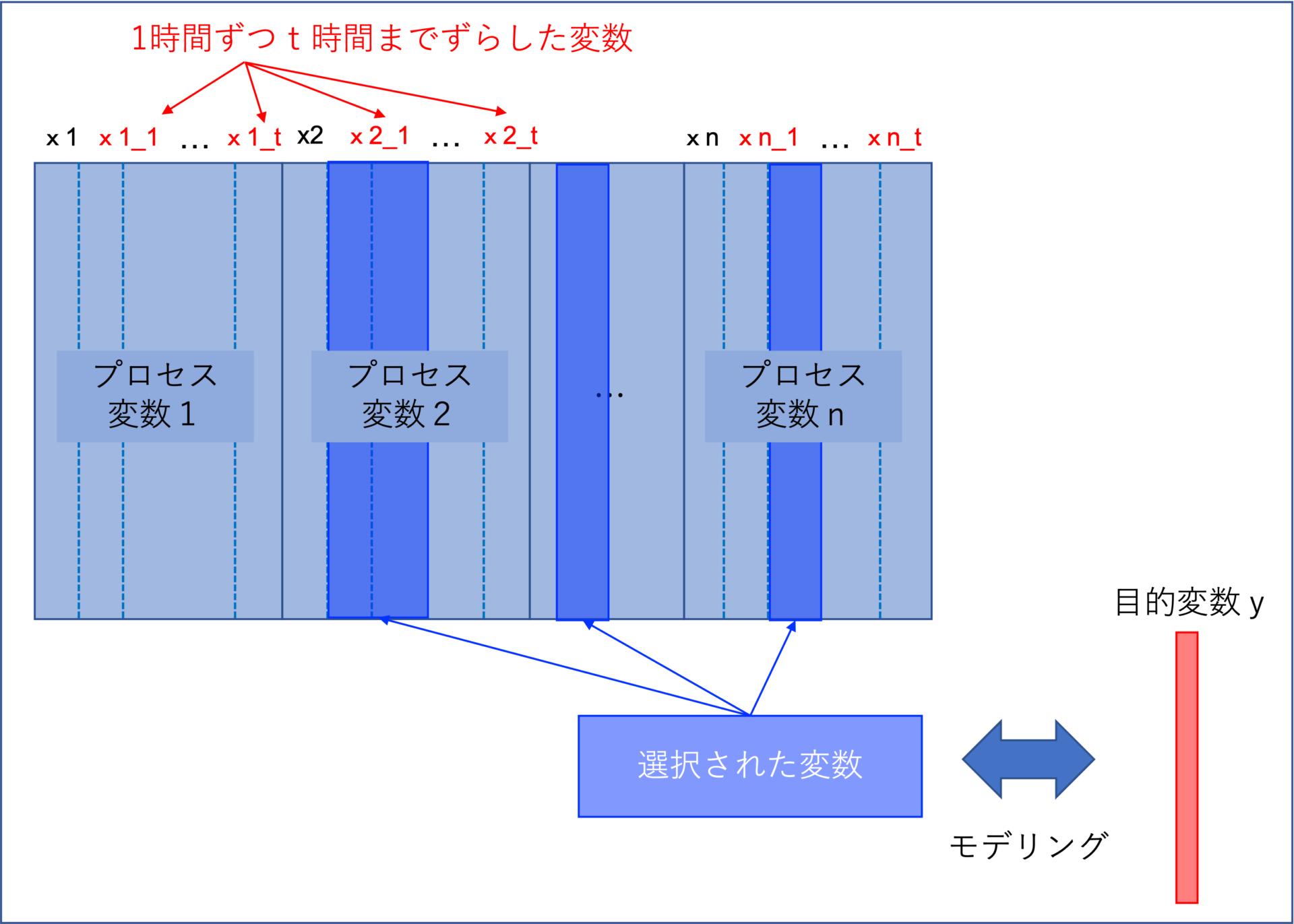
目的変数yと関係のないプロセス変数xはモデルの精度を低下させる要因となります。
そこで、目的変数yと関係の深いプロセス変数xの組合せのみでモデルを構築する手法が開発されています。
代表的な変数選択手法を下記にまとめました。
変数選択手法
- ステップワイズ法
- LASSO
- GAWLS法※ ※GA(遺伝的アルゴリズム)
- GAVDS法※
- PLS-VIP
- NCSC-VS
- Boruta
ステップワイズ法
ステップワイズ法は、プロセス変数xを取り込んだり取り除いたりしながら回帰モデルを構築し、ある評価指標が最適値となるような変数の組合せを探索する手法です。
評価指標としては、AICやBIC、RMSEなどが用いられます。
ステップワイズ法については、下記記事にまとめてあります。
-
-
【python】ステップワイズ法による入力変数選択
続きを見る

LASSO
LASSO回帰は、正則化項と呼ばれる罰則項を設けることで過学習を防止できます。
この正則化項は、回帰係数の大きさを制限する役割を果たしますが、特にLASSO回帰では回帰係数がゼロに収束しやすいことから変数選択手法としても活躍します。
LASSOについては、下記記事が図解があってわかりやすいです。
スパースモデリングはなぜ生まれたか? 代表的なアルゴリズム「LASSO」の登場
GA(遺伝的アルゴリズム)
遺伝的アルゴリズム(GA)は、自然界の進化を模倣して最適化問題を解決するアルゴリズムです。
GAWLSは、スペクトル解析分野において遺伝的アルゴリズムを用いて最適な波長を選択する手法です。
そして、GAVDSはGAWLSを改良し、プロセス動特性を考慮したプロセス変数選択に使えるようにした手法です。
GAWLSやGAVDSについては、下記記事が参考になります。
[Pythonコードあり] スペクトル解析における波長領域や時系列データ解析におけるプロセス変数とその時間遅れを選択する方法
PLS-VIP
Variable Importance for Projection (VIP) は、PLS (Partial Least Squares) モデルにおいて、各変数の予測モデルに対する寄与度を評価するための指標です。
VIPは、PLS モデル構築中の変数選択に役立ち、モデルの予測性能を向上させることができます。
参考に、LASSOやステップワイズ法、GA、PLS-VIPを比較した資料を紹介します。
NCSC-VS
NCSC 法は、相関識別法(Nearest Correlation Method; NC 法) とスペクトラルクラスタリング(SC) を組み合わせた手法で、変数間の相関関係に基づいてサンプルをクラスタリングします。
NCSC-VS(Nearest correlation spectral clustering based Variable Selection)は、NCSC法でクラスタリングしたグループ毎に変数選択をする手法です。
詳しくは下記文献を参照してください。
Boruta
Borutaは、全ての特徴量を含む仮想的な特徴量群(shadow features)を生成し、ランダムフォレストを用いて、実際の特徴量と仮想的な特徴量群の間で、有意な差異があるかどうかを検定します。
Borutaについては下記記事を参考にしてみてください。
[解析結果付き] Boruta、ランダムフォレストの変数重要度に基づく変数選択手法
また下記書籍には、ステップワイズ法やLASSO、PLS、PLS-VIP、NCSC-VSについて、理論的な解説とPythonコードが載っています。
とても勉強になったので、興味があれば読んでみてください。

5.xやyの変数変換
変数を解釈可能な次元に変換することも重要です。
例えば、ポリマー重合におけるMFR(Melt Flow Rate)をエネルギーの次元にするために対数変換することはよく知られています。
モデル構築
データの前処理が終わったら、いよいよモデル構築に移ります。
(実際は、モデル構築とデータ前処理は試行錯誤しながら同時に進めていきます。)
モデリング手法は大きく分けて3つに分類できます。
モデリング手法
- 物理モデル(ホワイトボックスモデル)
- 統計モデル(ブラックボックスモデル)
- ハイブリッドモデル(グレーボックスモデル)
物理モデルを構築することができれば理想的ですが、実際のプロセスでは様々な外乱が存在し、物理モデルで精度の良いソフトセンサーを作成できることは稀です。
よって、世の中の大半のソフトセンサーが統計モデルを採用しています。
一方、統計モデルにも弱点があり、モデル構築時のデータ範囲外である外挿領域においては予測精度が大きく落ちてしまいます。
そこで、化学的・物理的な知識を取り入れたハイブリッドモデルを採用し、外挿領域でも良好な予測精度を維持させる例もあります。
ソフトセンサーによく用いられる統計モデルを下表にまとめました。
| 線形回帰手法 | 非線形回帰手法 |
| 最小二乗法(OLS) | Kernel PLS |
| 主成分回帰(PCR) | 人工ニューラルネットワーク(ANN) |
| 部分的最小二乗回帰(PLS) | サポートベクター回帰(SVR) |
| リッジ回帰(RR) | ロジスティック回帰(LR) |
| LASSO | 回帰木(RT) |
| Elastic Net | ガウス過程回帰(GPR) |
| LightGBM |
ソフトセンサーの精度向上のため、これまで様々な統計モデルの研究が行われてきました。
1990年代は、PLSとニューラルネットワークの研究が盛んに行われ、2000年代になるとサポートベクター回帰(SVR)が注目されました。
2010年代からはガウス過程回帰(GPR)と勾配ブースティング(LightGBMなど)がソフトセンサー構築に使われるようになっています。
モデル解析
モデル解析では、モデルの解釈とモデルの検証を主に行います。
モデルの解釈
構築したモデルの目的変数yへのプロセス変数(説明変数)xの寄与度から、対象のプロセス知識を得ることができます。
これは、ソフトセンサーの役割であるプロセス変数間の関係の解明に繋がります。
モデルの検証
モデルの検証では、モデル構築用(学習用)データとは別の検証用データに対しての予測精度を確認します。
ここで過学習(オーバーフィッティング)の有無をチェックしておきましょう。
また、ソフトセンサーが十分な性能を発揮できるデータ範囲(モデルの適用範囲)を確認することも重要です。
モデルの適用範囲外では、予測精度が落ちてしまうことを理解しておく必要がありますね。
モデル運用
モデル運用のポイントは、下記の3点です。
モデル運用のポイント
- モデルの劣化
- データベース管理
- 予測誤差の推定
それでは、一つ一つ具体的に解説していきます。
1.モデルの劣化
ソフトセンサー作成において最も重要な問題が「モデルの劣化」です
下記のように、様々なプロセス特性の変化によってモデルの予測精度が低下してしまいます。
モデル劣化の要因
- 触媒の劣化
- 熱交換器や配管への汚れ付着
- 原料組成の変化
- 外気温の変化
- 各センサーの故障やドリフト(部品の経年劣化などにより、測定値が緩やかに変動すること)
など
ここで、モデルの劣化のイメージ図を示します。
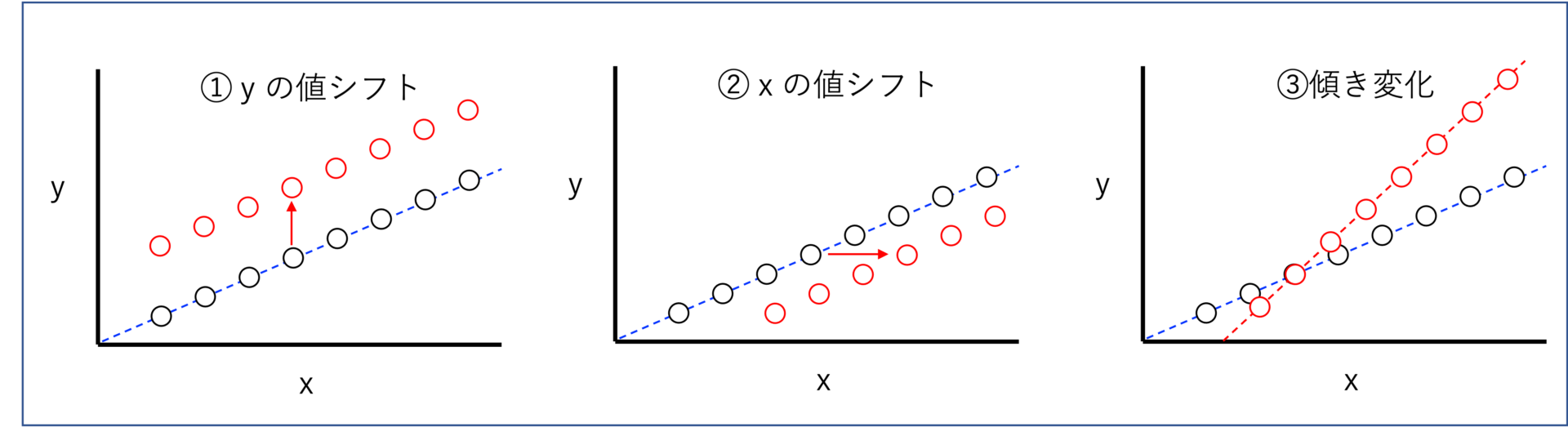
その他、プロセス特性の変化がA:徐々に起こる場合とB:急激に起こる場合にも分類できますね。
モデルの劣化への対応策
モデルの劣化への対応策
- 最新の運転データを用いてプロセス特性の変化にモデルを追随させる
⇒適応型モデル - モデルの劣化要因を特定し、それを踏まえたモデル構築・予測を行う
2.のようにモデルの劣化要因を特定し、それを踏まえたモデル構築・予測を行うのが理想です。
しかし、特定自体が難しいですし、要因が重なり合っている場合もあってなかなか難しいアプローチです。
よって、1.の適応型モデルの導入で対応するのが一般的です。
適応型ソフトセンサー
適応型モデルを用いたソフトセンサーを適応型ソフトセンサーと呼びます。
適応型モデルには下記3つの種類があります。
適応型モデル
①Moving Window(MW)
②Just-In-Time(JIT)
③Time Difference(TD)
それぞれの特徴を下記にまとめました。
①Moving Window(MW)
同じプロセス状態と考えられる直近のデータのみを用いてモデルを構築・更新していく適応型モデルです。
逐次モデルを更新していくので、古いデータの影響がモデルに残ります。
よって、モデル劣化の③傾きの変化には強いですが、①②の値シフトや急激な変化には弱いです。
②Just-In-Time(JIT)
プロセス変数xのデータ空間においてデータが近いとプロセス状態も近いと仮定する適応型モデルです。
類似したデータのみを用いてモデルを構築したり、類似度に基づいてデータに重み付けしてモデルを構築します。
類似度としては下記を想定しています。
- ユークリッド距離
- マハラノビス距離
- 相関係数
- カーネル関数
MWとは異なり、古いデータの影響を受けにくい特徴がありますが、①yの値シフトや③傾きの変化には弱いです。
また、データベースにあるデータとの類似度を計算する必要があるため計算負荷が大きいというデメリットがあります。
③Time Difference(TD)
単純にxとyの時間差分の間で構築された適応型モデルです。
モデル劣化は①②値のシフトに対応可能で、値のシフトであれば急激な変化にも対応できます。
モデルを再構築しないので、過去の異常値の影響も受けず、計算負荷も小さいという特徴があります。
一方、MWと異なり③傾きの変化に弱いのが弱点です
モデル劣化の種類に応じて、どの適応型モデルを使うべきか簡単に表にまとめてみました。
| モデルの劣化 | MWモデル | JITモデル | TDモデル | |
| 種類 | 速さ | |||
| ①yの値シフト | ゆっくり | ○ | × | ○ |
| 急激 | × | × | ○ | |
| ②xの値シフト | ゆっくり | ○ | ○ | ○ |
| 急激 | × | ○ | ○ | |
| ③傾き変化 | ゆっくり | ○ | × | × |
| 急激 | × | × | × | |
xとyの傾きが変化しない場合は、モデル再構築を行わず異常値の影響を受けにくいTDモデルを用います。
しかし、傾きが変化する場合には対応できないため、安定時はTDモデルを使用し、TDモデルの予測誤差が大きくなった場合のみMWモデルに切り替えるといった手法があります。
2.データベース管理
MWやJITといった適応型モデルでは、変動の少ない安定したデータでモデルが更新され続けると、その後に大きなプロセス変動が起こると予測精度が急激に悪化してしまいます。
よって、幅広いデータを用いてモデルを更新していく必要があり、データベースの適切な管理が重要です。
具体的には、新しいデータが得られた際にデータベースに保存するかどうか判断する指標を導入します。
これをDMI(Database Monitoring Index)と呼びます。
ガウシアンカーネルを用いたDMIを下式に示します。
$$\text{DMI} = \frac{|y_i - y_j|^a}{\text{exp}(- \gamma\|\mathbf{x_i} - \mathbf{x_j}\|^2)}\tag{2}$$
\(a\):\(x\)に対する\(y\)の重みを調整する変数
\(\gamma\):ガウシアンカーネルのパラメータ
二つのデータが類似しているとDMIは小さくなります。
新しいデータに対してデータベース内の全データとDMIを計算し、その最小値が閾値より大きい場合のみデータベースに追加します。
しかし、DMIによるデータベース管理だけでは、「異常値」を取り除くことができず、異常値をモデルに混入させてしまうことでモデルの予測精度を悪化させてしまいます。
そこで、異常検出を考慮しながらデータベース管理をする必要があります。
例えば、異常検出モデルとして下記のような手法が用いられます。
- 独立成分分析(ICA)
- サポートベクターマシン(SVM)
- 局所外れ値因子法(LOF)
- アイソレーションフォレスト(iForest)
3.予測誤差の推定
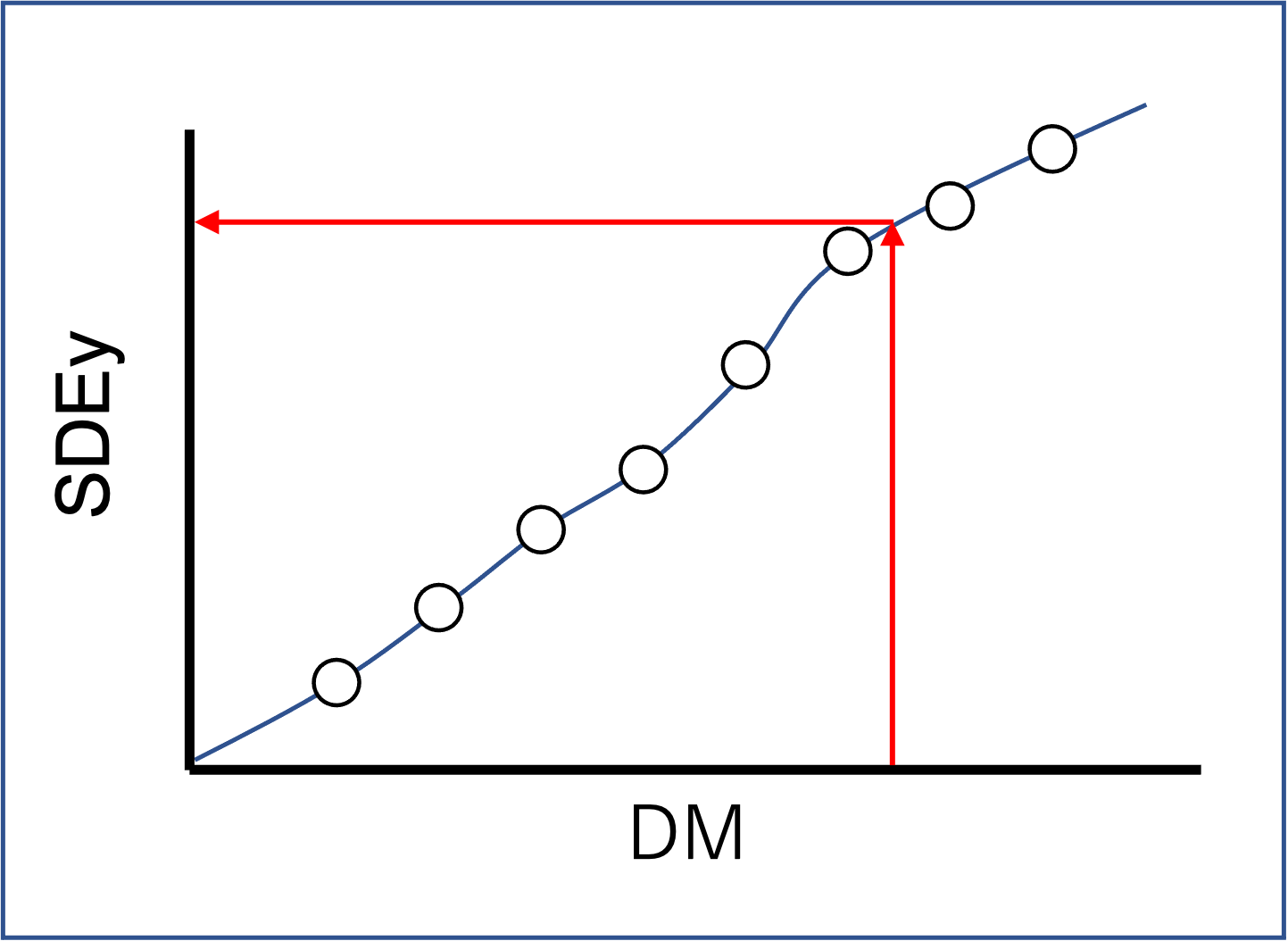
ソフトセンサーの運用では、ソフトセンサーの予測誤差がどの程度かを把握することが重要です。
今までにない運転条件であれば当然予測精度が落ちますし、想定していた予測誤差よりも実測値が大きくズレるような場合は、分析計の異常を疑う必要があります。
そこで、予測誤差を推定する具体的な方法を解説します。
予測誤差の推定方法
1)モデル構築用データで予測誤差(=yの予測値-実測値)を算出
2)モデル構築用の全データでDM※を算出
※DM:新しいデータとモデルとの距離(Distance to Model:DM)
DMの例)ユークリッド距離やマハラノビス距離
3)DMの小さい順にデータを並べ替える
4)並べ替えたあとのデータについて、(i - m)番目から(i + m)番目のデータの予測誤差の標準偏差(SDEy)を計算
※mは事前に設定するパラメータ(m≧50)
※SDEy:Standard Deviation of prediction Errors of y
5)SDEyとDMのグラフを作成(上図参照)
6)新しいデータが得られたらDMを計算し、5)のグラフからSDEyを推定
参考文献
本記事は、こちらの教科書を参考に書きました(良書だったので、2周読みました!)
ソフトセンサーの作成方法などについて興味がありましたら、ぜひ読んでみて下さい!
pythonコードが非常に充実しており、化学系エンジニアがPythonを使ってデータ解析するなら、まず手に取って欲しい一冊です!
本書は、理論的な部分も詳しく解説してくれて、かつPythonコードも載っているのでとても気に入っている教科書です。
学べる内容
- LASSO
- PLS
- PLS-VIP
- ステップワイズ法
- NCSC-VS