どうも。こんにちは。
ケミカルエンジニアのこーしです。
本日は、化学プロセスのサンプルデータ入手方法について解説します。
データ解析を勉強する際、サンプルデータを用いることが多いです。
しかし、化学プロセスのような時系列のサンプルデータはなかなか見つかりません。
そこで本記事では、化学プロセスのサンプルデータの入手方法をまとめてみました。
データの前処理やモデル構築を勉強する際に、参考にしていただけたらと思います。
【追記】GitHubにコードとサンプルデータ(csv変換済み)をまとめておきました。
本記事の内容
・TEP(Tennessee Eastman Process)データ
①RData形式
②DATファイル
・脱ブタン塔データ
・酢酸ビニルモノマー(VAM)プラントデータ
・参考文献
この記事を書いた人
 こーし(@mimikousi)
こーし(@mimikousi)
TEP(Tennessee Eastman Process)データ
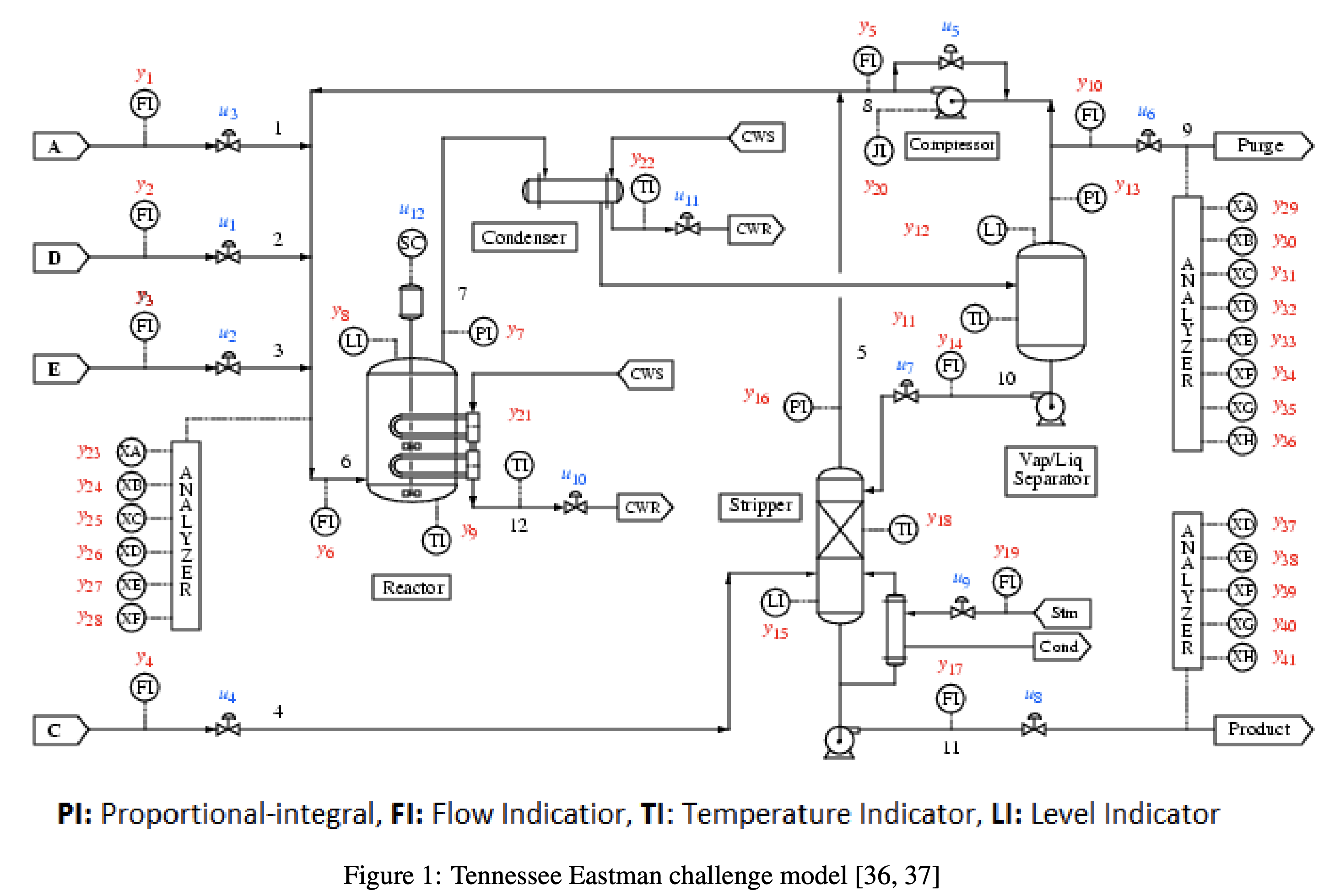
上図は、Tennessee Eastman Process(TEP)のプロセスフローダイアグラム(PFD)です。
TEPは下記5つの主要機器からなるプロセスで、A,C,D,Eの4つの原料から化学反応によってG,Hの2つの製品を製造します。
- 反応器(Reactor)
- 凝縮器(Condenser)
- 精留塔(Stripper)
- 気液分離機(Vap/Liq Separator)
- コンプレッサ(Compressor)
データの内容
- TEPは52変数
12個の操作変数xmv(図の青字)、41個の観測変数xmeas(図の赤字)
※xmv12が省略されているので、データは52変数 - 3分周期の48時間データ(データ数n=960)
RData形式
まずは、RData形式のデータを取得してみましょう。
下記のリンクから、TEPデータをRData形式でダウンロードできます。
Additional Tennessee Eastman Process Simulation Data
ダウンロード手順
①「TEP_FaultFree_Testing.RData」と「TEP_Faulty_Testing.RData」にチェックを入れてダウンロードを押します。
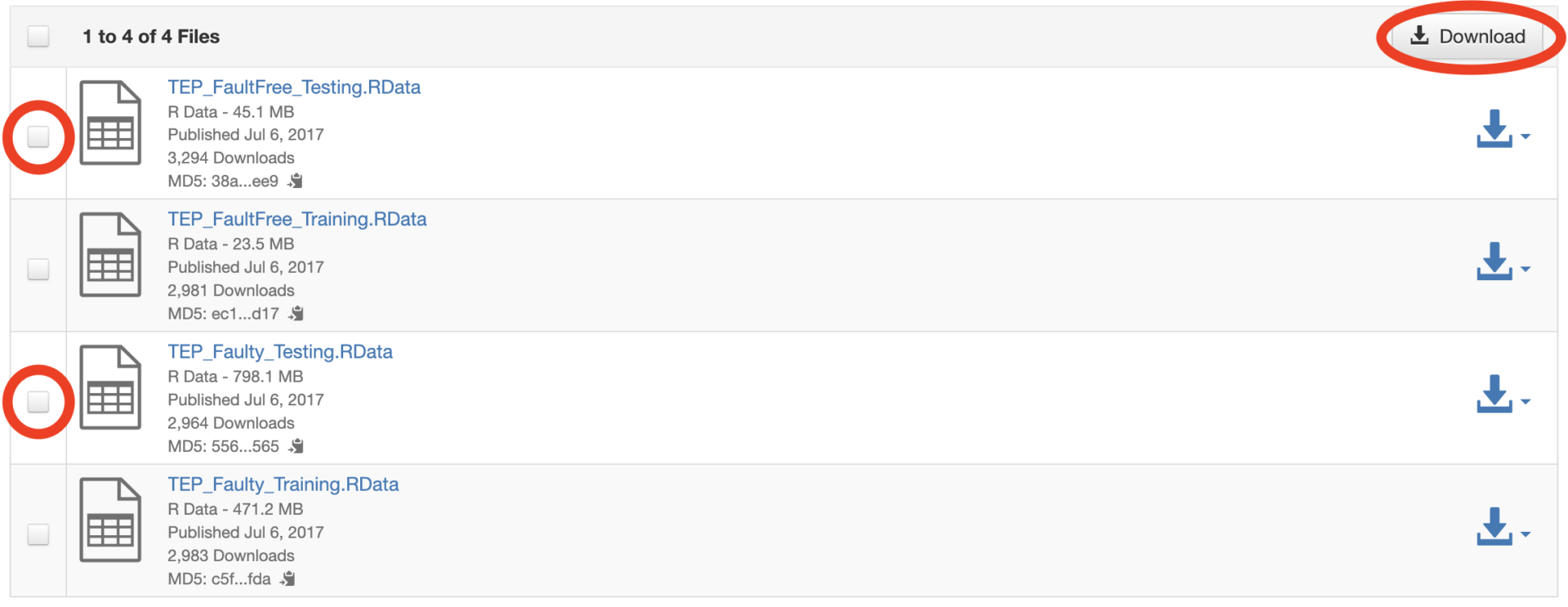
②zip形式でダウンロードされるので、解凍しましょう。
ただし、解凍したファイルはRData形式なので、pythonでcsvファイルに変換します。
csvファイル化(RData→csv)
①rdataパッケージをpip installでインストールします。
コマンドプロンプト(Windows)かterminal(Mac)に以下のコードを入力します。
$ pip install rdata
※先頭の$は入力する必要はありません。
本記事では、先頭に$マークをつけることでpythonコードと異なることを示しています。
②rdataパッケージをインストールしたら、pythonでcsvファイルに変換します。
「sample_data.py」というファイルを作成し、以下のコードを入力しましょう。
import rdata
import pandas as pd
# RData 形式の読み込み
train_parsed = rdata.parser.parse_file('TEP_FaultFree_Testing.RData')
train_converted = rdata.conversion.convert(train_parsed)
test_parsed = rdata.parser.parse_file('TEP_Faulty_Testing.RData')
test_converted = rdata.conversion.convert(test_parsed)
# csv ファイルに変換
# 学習用データ
train_data = pd.DataFrame(train_converted ['fault_free_testing'])
train_data = train_data.iloc [0:960, 3:]
train_data.to_csv('normal_data.csv', index = False)
# パラメータチューニング用データ
tuning_data = pd.DataFrame(train_converted ['fault_free_testing'])
tuning_data = tuning_data.iloc [960:1920, 3:]
tuning_data.to_csv('tuning_data.csv', index = False)
# 異常データ
test_data = pd.DataFrame(test_converted ['faulty_testing'])
# 異常ごとに分割してcsv 形式で出力
for i in range(1, 21):
idv_data = test_data [test_data ['faultNumber'] == i]
idv_data = idv_data.iloc [0:960, 3:]
title_name = 'idv '+ str(i)+ '_data.csv'
idv_data.to_csv(title_name, index = False)
先ほどダウンロードした「TEP_FaultFree_Testing.RData」と「TEP_Faulty_Testing.RData」を「sample_data.py」と同じフォルダに置いてください。
TEPデータが格納された「normal_data.csv」と「tuning_data.csv」、また20個の異常データ「idv ○_data.csv」(○に数字が入る)が作成されます。
ちなみに、pythonの環境構築については下記の記事を参考にしてみてください。
VScodeがおすすめです。
-

-
【初心者向け】おすすめのpython環境構築方法
続きを見る

DATファイル
RData形式は、スモールデータ解析と機械学習で紹介されていた方法でした。
一方、化学のためのPythonによるデータ解析・機械学習入門では、DATファイルでTEPデータを入手する方法が紹介されています。
ダウンロード手順
①まず、GitHubのページにアクセスします。
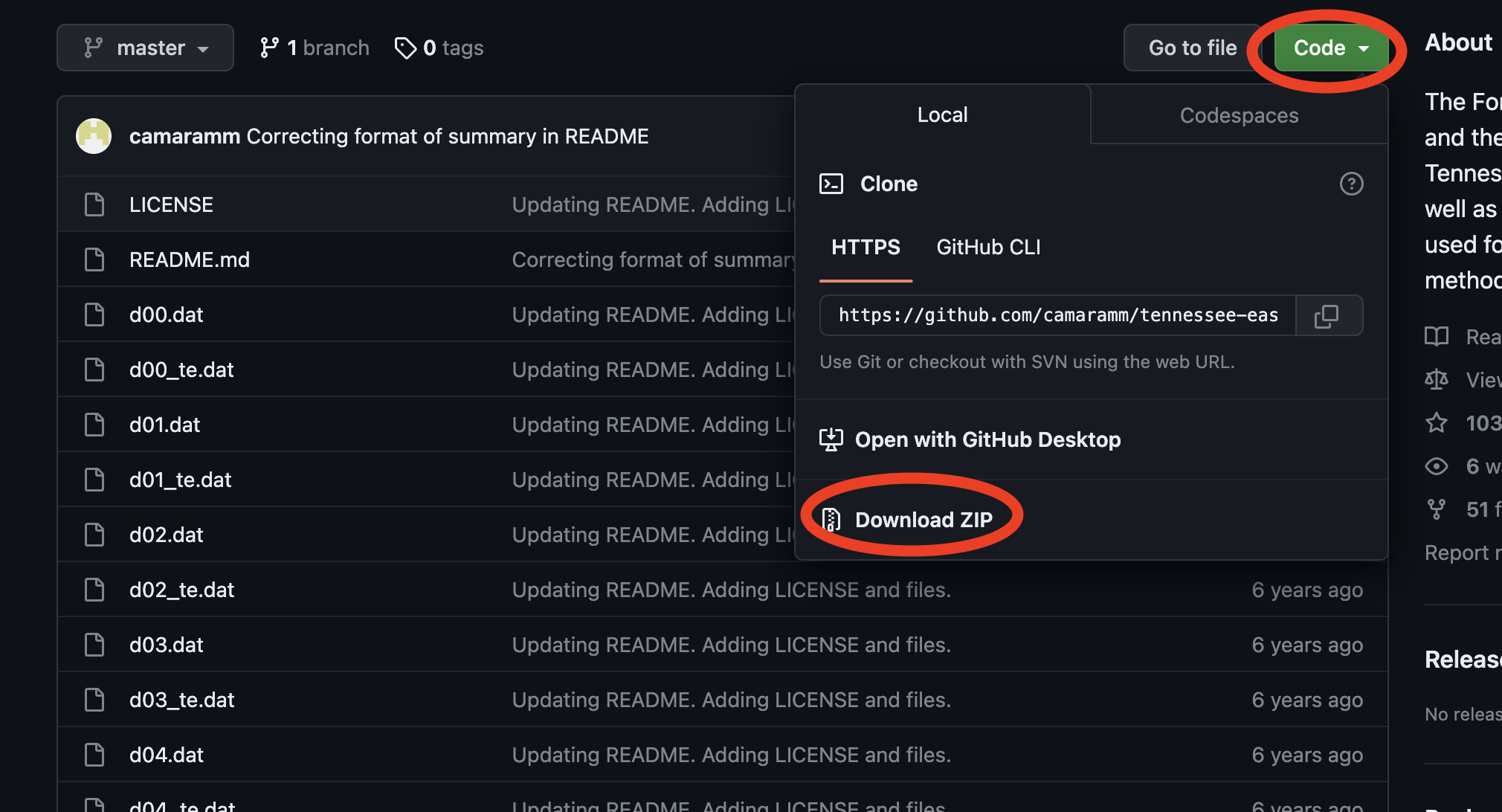
②「code」ボタンを押すと「Download ZIP」が出てくるので、zipファイルをダウンロードしましょう。
③zipファイルを解凍すると下図のようにDATファイルが入手できます。
フォルダ名「tennessee-eastman-profBraatz-master」
csvファイル化(DATファイル→csv)
続いて、DATファイルをpythonでcsvに変換しましょう。
「tennessee-eastman-profBraatz-master」フォルダと同じディレクトリ(フォルダ)に、「sample_data_dat.py」というファイルを作成し、以下のコードを入力しましょう。
import pandas as pd
#変数名のリストを作成します
columns = ['xmeas_1', 'xmeas_2', 'xmeas_3', 'xmeas_4', 'xmeas_5', 'xmeas_6',
'xmeas_7', 'xmeas_8', 'xmeas_9', 'xmeas_10', 'xmeas_11', 'xmeas_12',
'xmeas_13', 'xmeas_14', 'xmeas_15', 'xmeas_16', 'xmeas_17', 'xmeas_18',
'xmeas_19', 'xmeas_20', 'xmeas_21', 'xmeas_22', 'xmeas_23', 'xmeas_24',
'xmeas_25', 'xmeas_26', 'xmeas_27', 'xmeas_28', 'xmeas_29', 'xmeas_30',
'xmeas_31', 'xmeas_32', 'xmeas_33', 'xmeas_34', 'xmeas_35', 'xmeas_36',
'xmeas_37', 'xmeas_38', 'xmeas_39', 'xmeas_40', 'xmeas_41', 'xmv_1',
'xmv_2', 'xmv_3', 'xmv_4', 'xmv_5', 'xmv_6', 'xmv_7', 'xmv_8', 'xmv_9',
'xmv_10', 'xmv_11']
#異常なしデータ(d00_te.csv)と21個の異常データ(d〇_te.csv)をcsvファイルにします。※〇に数字が入ります。
for i in range(22):
df = pd.read_table(f'./tennessee-eastman-profBraatz-master/d{i:02}_te.dat', sep=' ', header=None ,engine='python')
df.columns = columns
title_name = f'd{i:02}_te.csv'
df.to_csv(title_name, index = False)
正常データ「d00_te.csv」と21個の異常データ「d○_te.csv」(○に数字が入る)が作成されます。
ちなみに、データの区切り(sep=' ')は、スペース2つ分としています。
データの区切りにスペースを使うと警告が出るため、engine='python'を引数に記載しています。
脱ブタン塔データ
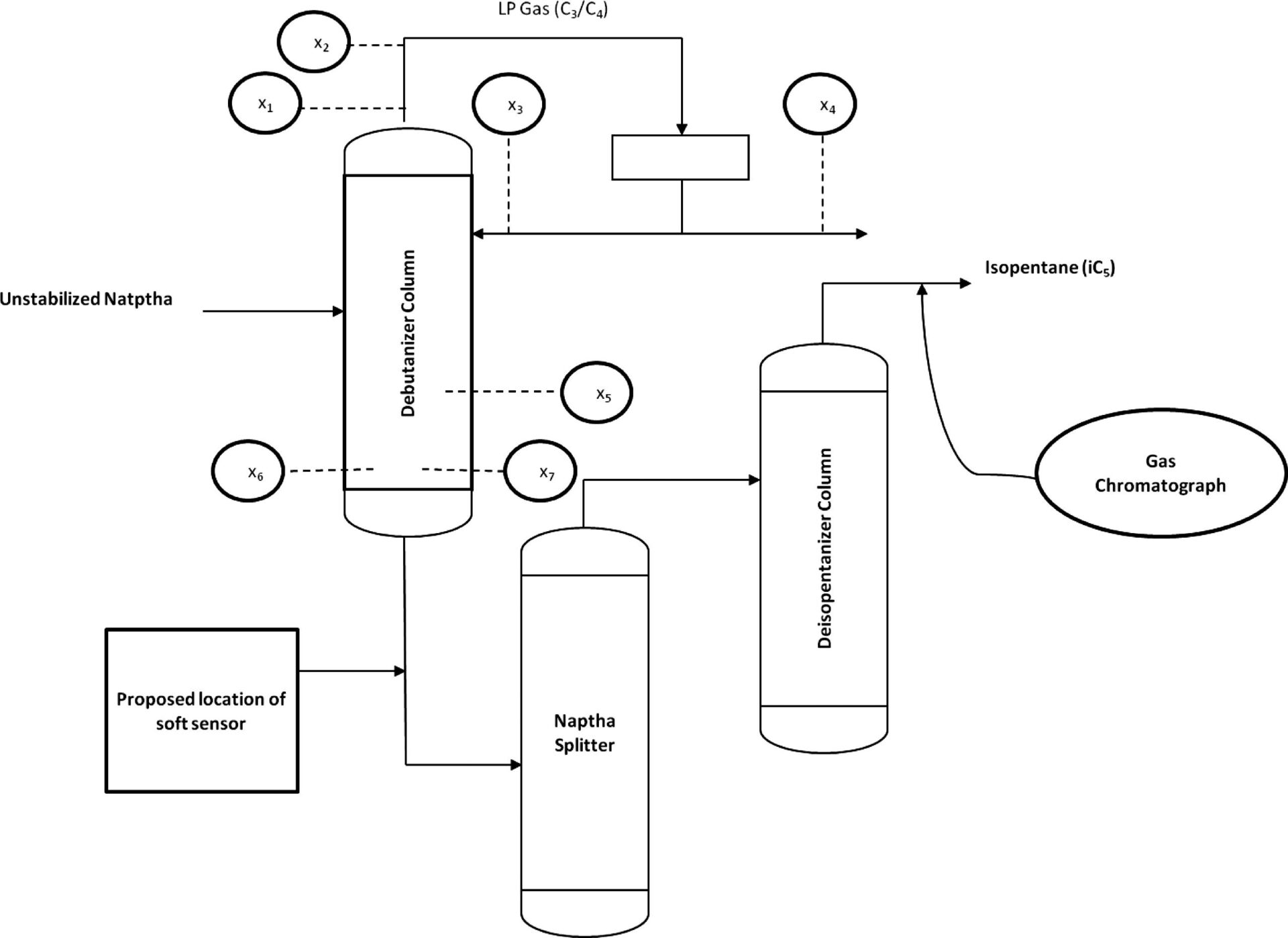
上図が脱ブタン塔のプロセスフロー概略図です。
ナフサを脱ブタン塔に供給し、塔頂からLPガス(C3/C4)が得られます。
塔底にも一部ブタン(C4)が含有してしまうため、「塔底におけるブタン含有量」を目的変数(観測変数)yとしています。
| 変数名 | 詳細 | 日本語訳 |
|---|---|---|
| x1 | Top Temperature | 塔頂温度 |
| x2 | Top pressure | 塔頂圧力 |
| x3 | Reflux flow | 還流流量 |
| x4 | Flow to next process | 次プロセスへの流量 |
| x5 | 6th tray Temperature | 6段目温度 |
| x6 | Bottom Temperature1 | 塔底温度1 |
| x7 | Bottom Temperature2 | 塔底温度2 |
| y | Butane(C4) content in the debutanizer column bottom | 塔底におけるブタン含有量 |
プロセス詳細はこちらの論文を参照してください。
データの内容
- 脱ブタンプロセスは8変数
7個の操作変数(x1〜x7)と、1個の観測変数(y) - 6分周期(仮)の約10日間データ(データ数n=2394)
ダウンロード手順
脱ブタン塔のデータについては、下記書籍の付属データを使用します。
Soft Sensors for Monitoring and Control of Industrial Processes
①まず、書籍のサポートページにアクセスします。
②下図を参考に、ダウンロードボタンを押してzipファイルをダウンロードしましょう。
③zipファイルを解凍すると「9781846284793_material.zip」が出てくるので、もう一度解凍しましょう。
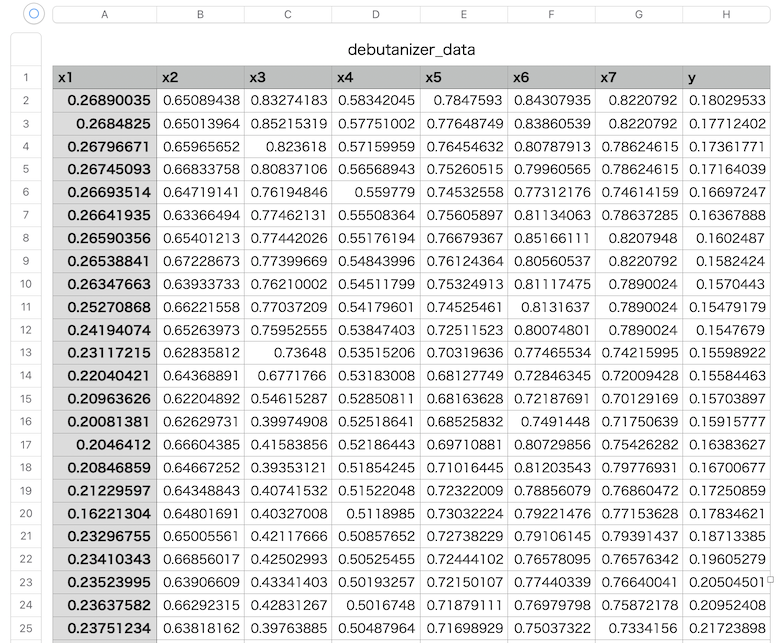
すると、脱ブタン塔のデータ「debutanizer_data.txt」が得られます(SRU_data.txtもあります)。
csvファイル化(テキストファイル→csv)
「sample_data_debu.py」というファイルを作成し、以下のコードを入力しましょう。
import pandas as pd
#変数名のリストを作成します
columns = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'y']
#txtファイルをcsvファイルに変換します。
df = pd.read_table('debutanizer_data.txt', skiprows=2, sep=' ',header=None, engine='python')
df.columns = columns
df.to_csv('debutanizer_data.csv', index=False)
脱ブタン塔データ「debutanizer_data.csv」が作成されます。
ちなみに、データの区切り(sep=' ')は、スペース2つ分としています。
データの区切りにスペースを使うと警告が出るため、engine='python'を引数に記載しています。
酢酸ビニルモノマー(VAM)プラントデータ
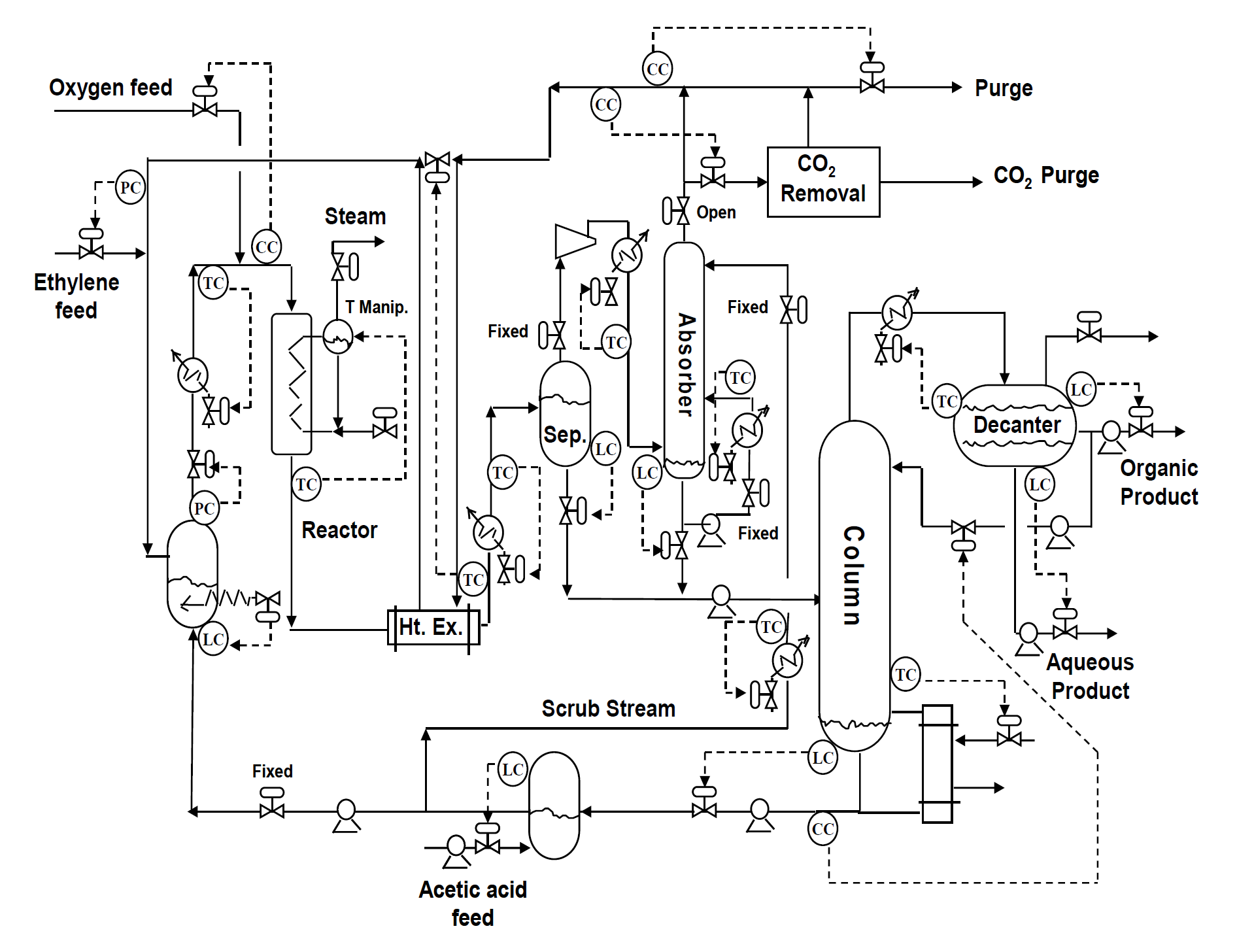
ごちきかで紹介されている酢酸ビニルモノマー(VAM)プラントデータ(シミュレーション)です。
下記の記事から、csvファイルがダウンロードできます。
データの説明については、プロセス制御とデータ分析のページに記載があります。
酢酸ビニルモノマーのシミュレーションデータに関する論文はコチラです。
データの中身をより詳しく知りたくなったら、参考にしてみてください。
参考文献
本記事では、下記2冊を参考にさせてもらいました。
化学プロセスのデータ解析を勉強するなら、欠かせない2冊だと思います!
記事冒頭にも書きましたが、GitHubにpythonコードとサンプルデータ(csv変換済み)をまとめておきました。