
どうも。こんにちは。
ケミカルエンジニアのこーしです。
本日は、「pandasによるプロセスデータの抽出方法」についてわかりやすく解説します。
製造業では、膨大なプロセスデータを分析して生産性を向上させることが重要です。
しかし、そのデータを効果的に活用するためには、適切な抽出と解析が欠かせません。
そこで、本記事ではpythonのpandasライブラリを用いて、プロセスデータを抽出する方法について解説します。
特に、特徴量(列)を指定して抽出したり、期間(行)を指定して抽出する方法を詳しく解説します。
pandasデータフレームを用いたデータの効率的な取り扱いについて学びましょう!
本記事の内容
・プロセスデータのサンプル作成方法
・特徴量(列)の指定によるデータの抽出
・期間(行)の指定によるデータの抽出
・特定条件データの抽出
・参考文献
この記事を書いた人
 こーし(@mimikousi)
こーし(@mimikousi)
目次
プロセスデータのサンプル作成方法
プロセスデータは、一番左の列に日付データがあり、その右の列に説明変数や目的変数が並んでいます。
サンプル作成方法
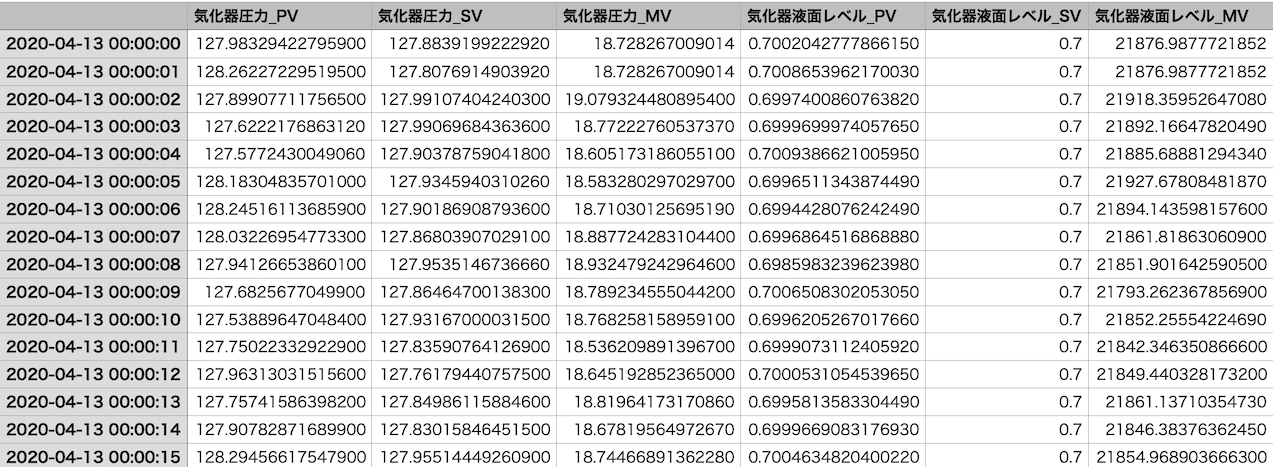
上記のプロセスデータは、酢酸ビニルモノマー(VAM)プラントのデータです。
下記の記事から、csvファイルがダウンロードできます。
データの内容
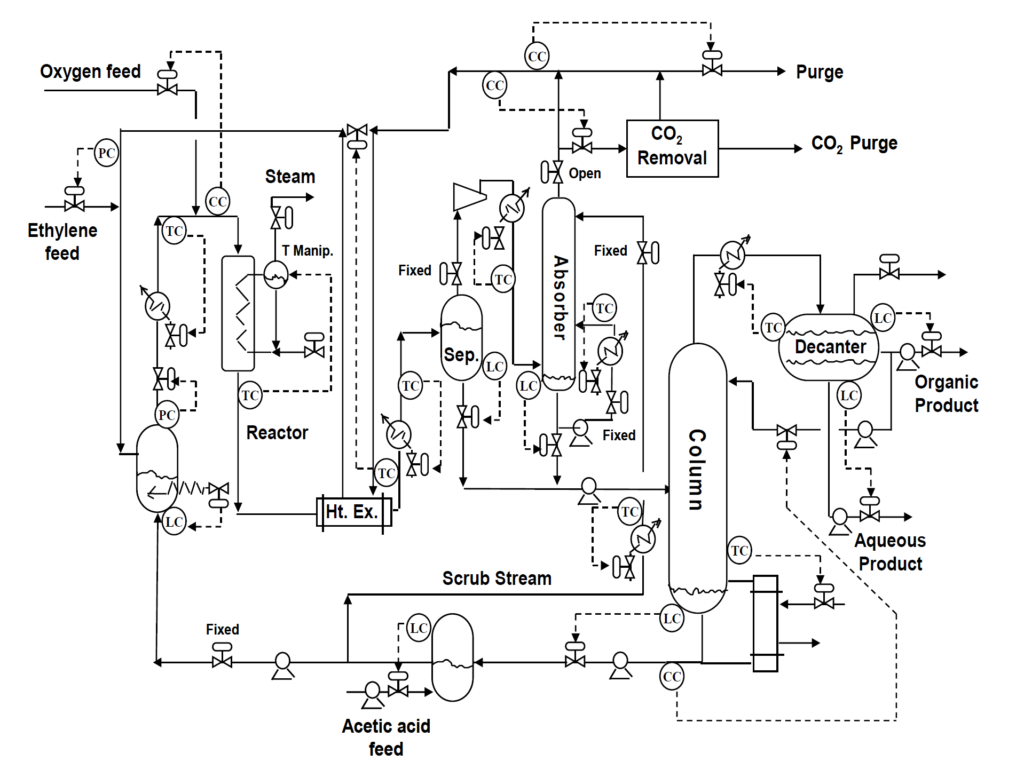
上図が酢酸ビニルモノマー(VAM)プラントのプロセスフロー図です。
データの説明については、プロセス制御とデータ分析のページに記載があります。
データの内容は本記事に直接関係ありませんが、詳しく知りたくなったらコチラの論文を参照してみてください。
また、他のプロセスデータを使ってみたいと思う方は、下記記事も参考にしてみてください。
-

-
【Python】化学プロセスのサンプルデータ入手方法
続きを見る

データの読み込み
早速、プロセスデータをpythonで読み込んでみましょう。
「2020413.csv」と同じフォルダに「data_extraction.ipynb」というファイルを作成し、下記のコードを入力します。
本記事では、結果を見ながらの方が理解しやすいため、jupyter notebookを使用します。
import pandas as pd
#表示する列数を増やす
pd.set_option('display.max_columns', 100)
#データを読み込みます
df = pd.read_csv('2020413.csv', index_col=0, header=0, encoding='shift-jis')
#読み込んだデータの先頭5行を表示
df.head()
データの列名(columns名)に日本語があるため、encoding='SHIFT-JIS'を引数に指定し、文字化けを防ぎます。
特徴量(列)の指定によるデータの抽出
プロセスデータは、たくさんの計測機器のデータを含んでおり、説明変数(特徴量)xが多いのが特徴です。
よって、列を指定してデータを抽出する操作が必要です。
まず、どんな列名があるのか確認してみましょう。
df.columns
結果は下図の通りです。
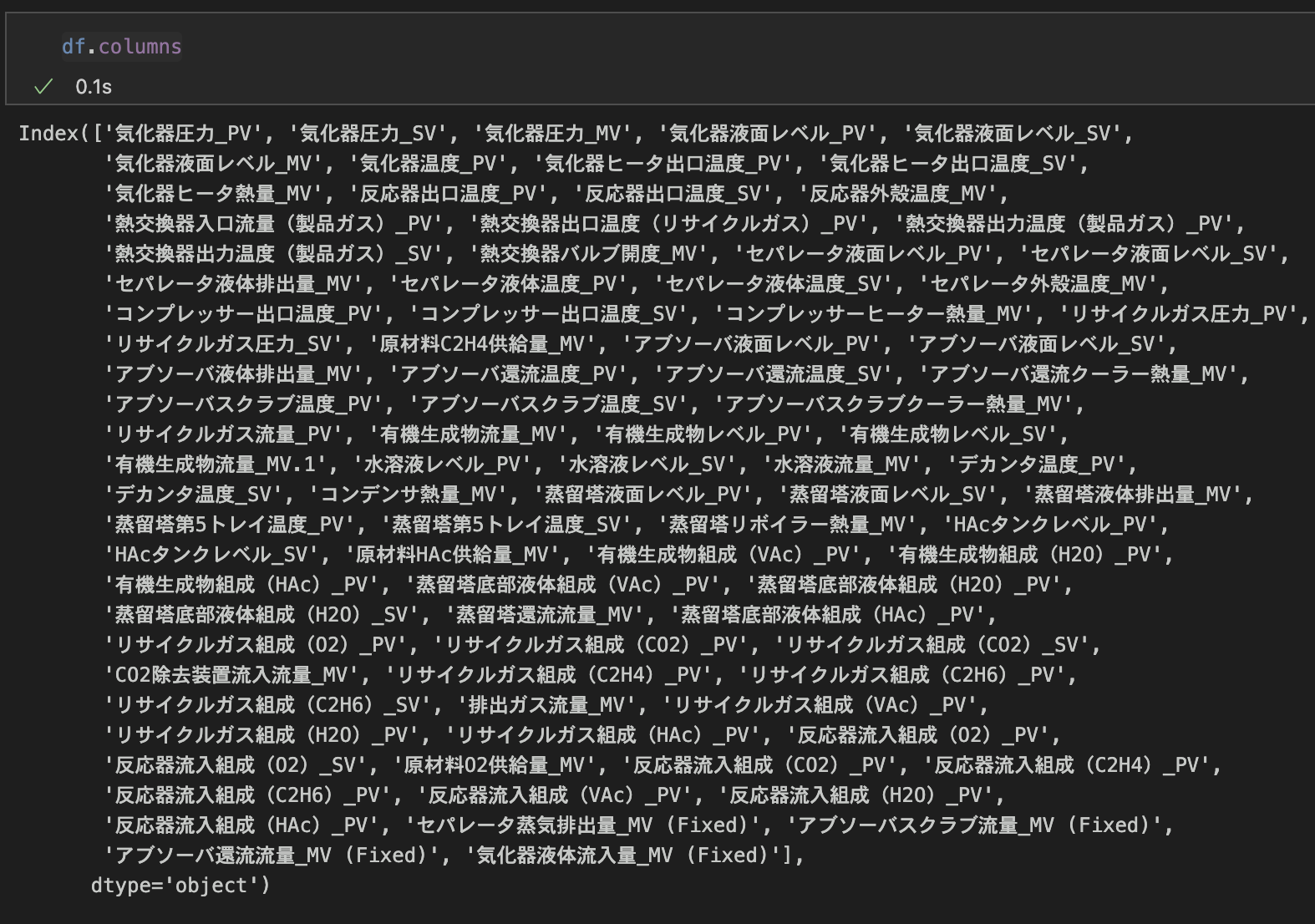
列の名称(columns名)を指定して抽出
抽出したい特徴量(列)が少ない場合は、列名を指定してデータを抽出しましょう。
df['気化器圧力_PV']
複数の列を抽出したい場合は、複数の列名をリストの形[]で指定します。
df[['気化器圧力_PV', '気化器液面レベル_PV']]
列名のリストを指定して抽出
抽出したい列が多い場合は、列の名称をリストにしてから、そのリストを指定してデータを抽出します。
select_list = [
'気化器圧力_PV',
'蒸留塔還流流量_MV',
'セパレータ外殻温度_MV',
'HAcタンクレベル_PV',
'反応器流入組成(VAc)_PV'
]
df[select_list]
locメソッド
ここで、何かと便利なlocメソッドを紹介します。
locメソッドでは、df.loc[行名,列名]のように行名や列名を指定することでデータを抽出できます。
df.loc[:, ['気化器圧力_PV', '気化器液面レベル_PV']]
ここで、行名はすべてを表す:(スライス)を指定しています。
行名を指定して抽出する方法は後述します。
また、下記のように列名のリストを指定することもできます。
df.loc[:, select_list]
locメソッドは、とても便利なのでぜひ使ってみてください。
ちなみに、よく似たメソッドでilocメソッドがあります。
ilocメソッドは、行名や列名ではなく、インデックス番号を指定します。
【参考記事】Pandas locと ilocの違いとは?
dropメソッド
逆に、必要な列が大多数であり、いらない列の方が少ない場合は、いらない列の指定してデータを抽出しましょう。
dropメソッドを使用します。
drop_list = [
'リサイクルガス組成(C2H6)_SV',
'排出ガス流量_MV'
]
df.drop(drop_list, axis=1)
引数にaxis=1を指定しないとエラーが出るため注意してください。
期間(行)の指定によるデータの抽出
locメソッド
期間(行)を指定してデータを抽出する場合は、locメソッドを使いましょう。
df.loc[行名,列名]の形で、期間(行名)を指定してデータを抽出します。
df.loc['2020-04-13 15:00:00', :]
期間(行名)は文字列なので、' 'で囲う必要があるため、ご注意ください。
また、「何時から何時」のように、ある範囲の期間を指定したい場合がほとんどです。
そこで、スライス(:)を用いて、ある範囲の期間を指定してみましょう。
df.loc['2020-04-13 00:00:00':'2020-04-13 01:00:00', :] df.loc[:'2020-04-13 01:00:00', :] df.loc['2020-04-13 01:00:00':, :]
上記のように、スライス(:)を用いることで様々な範囲のデータを抽出することができます。
特定条件データの抽出
運転に異常があった期間とか、データが上手く保存できてなかった期間のデータをまるごと除いてデータ抽出したいときが多々あります。
特定条件の例
- 気化器温度_PV > 121
- 気化器圧力_PV < 127.5
上記の特定条件について、データを抽出してみましょう。
df[df['気化器温度_PV'] > 121]
複数条件は括弧()と&を使って指定します。
df[(df['気化器温度_PV'] > 121) & (df['気化器圧力_PV'] < 127.5)]
(例)標準偏差が0の特徴量データを削除
プロセスデータには設定値(Setting Value:SV)が含まれます。
例えば、液面(レベル)の設定値はほとんど変えないため、回帰分析をする際に不要だったりします。
下記のようなコードを書いて、標準偏差が0の特徴量名(列名)を抽出しましょう。
drop_list =df.columns[df.std() == 0] drop_list

続いて、dropメソッドを使って特徴量名(列名)のリストを指定します。
df_ = df.drop(drop_list, axis=1) df_
これで、標準偏差が0の特徴量以外のプロセスデータを抽出することができました。
参考文献
「Python 3 エンジニア認定データ分析試験」の公式教材です。
基礎がわかりやすく解説してあり、python初心者にオススメの1冊です。
化学系のデータ解析について書かれた本です。
前著「化学のためのPythonによるデータ解析・機械学習入門」と合わせて読むと、実務で使えるレベルのデータ解析力が身につきます。