どうも。こんにちは。
ケミカルエンジニアのこーしです。
本日は、Pythonによるデータの読み込み方法について解説します。
本記事では化学プラントの運転・品質データ(csv,excel)を例に、Pythonのpandasライブラリを使ったデータ読み込み方法を解説していきます。
本記事の内容
・データのイメージ図
・pandasによるデータの読み込み
・絶対パス/相対パス
・日本語を含むファイルの読み込み
・index名,columns名の変更
・時系列データの注意点(データ型)
この記事を書いた人

こーし(@mimikousi)
データのイメージ図
化学プラントで扱うデータは、大きくわけて下記2つに分類できます。
データの種類
- プロセスのセンサデータ(excel or csvデータ)
- ラボ分析データ(手入力データ)
それでは、具体的にデータのイメージ図を見てみましょう。
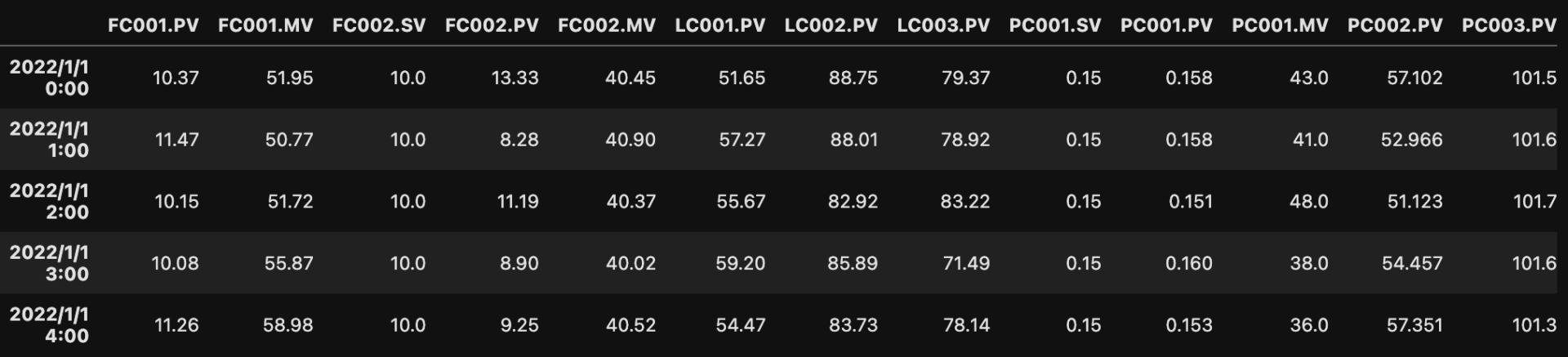
プロセスのセンサデータ
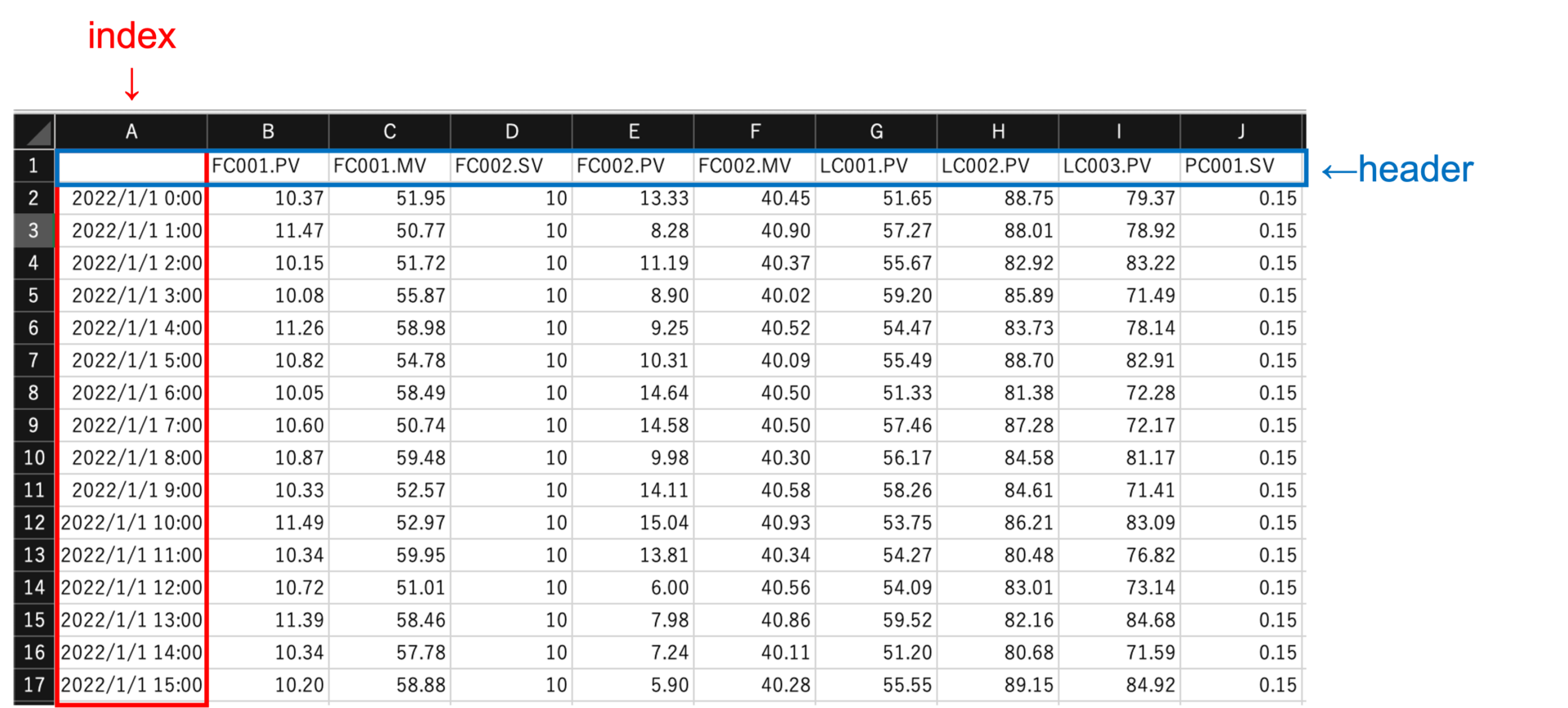
プロセスのセンサデータは、時系列データに該当します。
基本的に「1分間隔」でデータベースに保存していることが多いですが、工場によっては5分間隔のところもあります。
上図では、1時間平均値に加工したデータを表示しています。
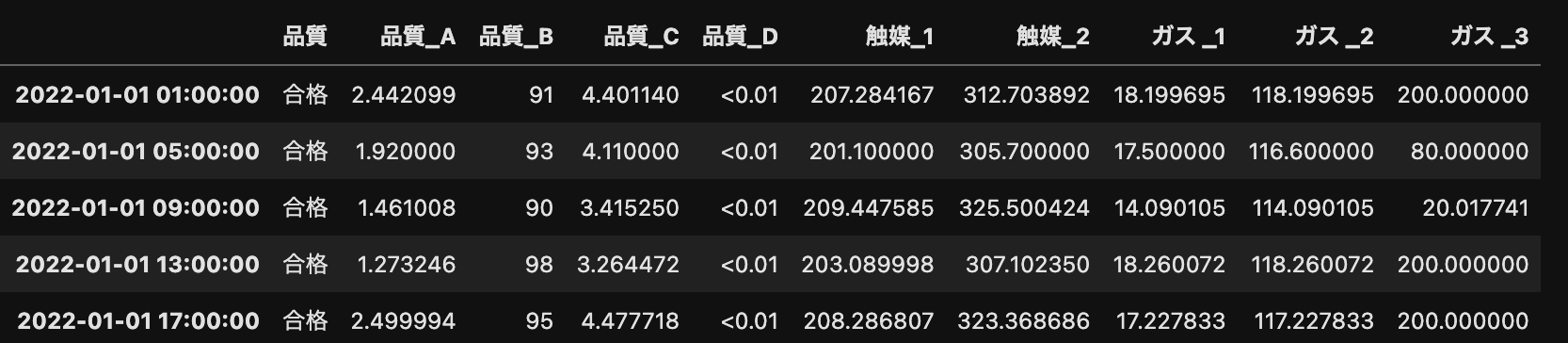
ラボ分析データ(手入力データ)
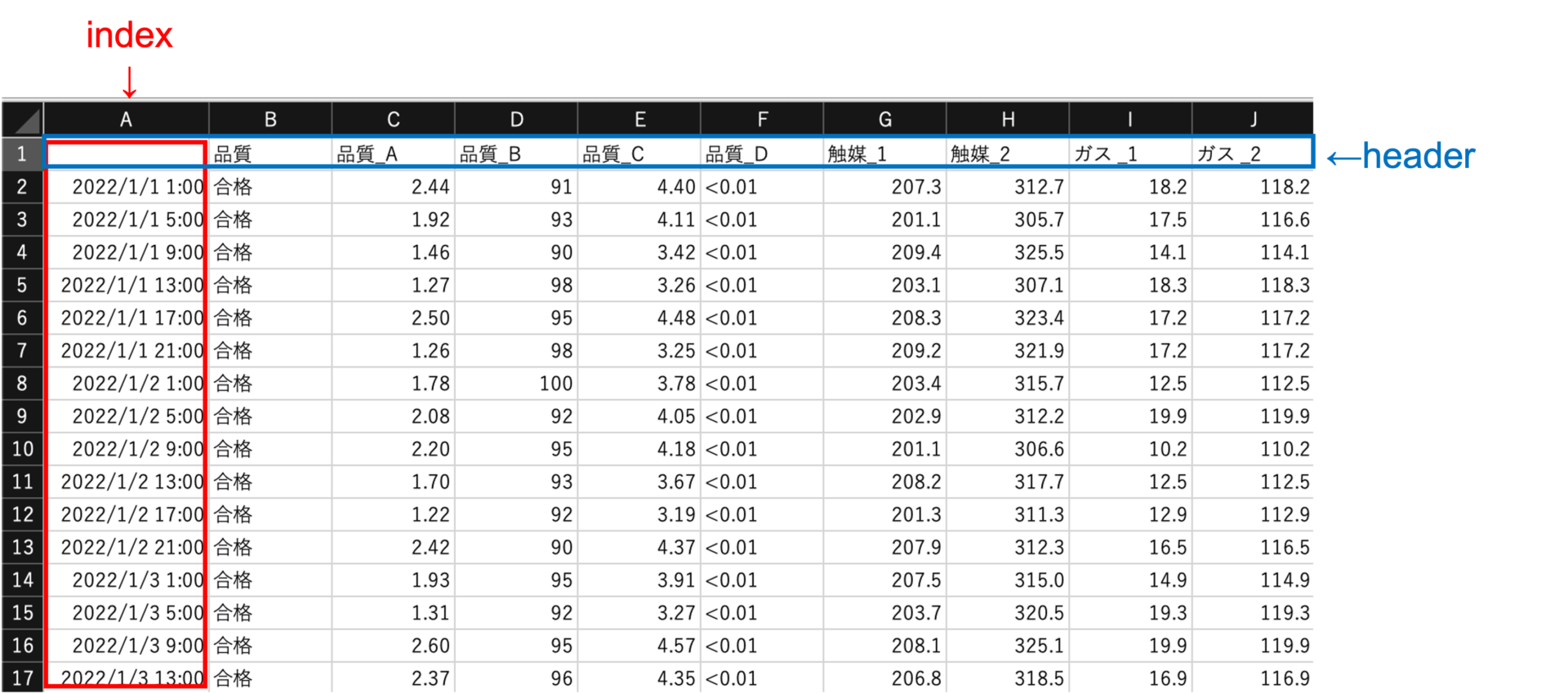
ラボ分析データも、時系列データに該当します。
分析して得られたデータをExcelなどに手入力します。
上図は、4時間おきにサンプリングして分析したデータになります(現実には30分とか1時間ズレたりします)。
プロセスのセンサデータは機械的にデータを蓄積していくのに対し、ラボ分析データは、ヒトによる手入力でデータが蓄積されていきます。
よって、プロセスのセンサデータを使って品質の回帰分析などを行う際は、「データ結合」が必要になります。
pandasによるデータの読み込み
pythonでデータを読み込むには、pandasというライブラリを使用します。
pandas公式ドキュメントはコチラ
注意ポイント
本記事では、jupyter notebookか、jupyter labを使用する前提とします。
また、excelデータを扱うにはopenpyxlライブラリ※のインストールが必要です。
※anacondaならインストール済み
それでは、下記のようなファイル名のデータを読み込んでみましょう。
- プロセスのセンサデータ ⇒ sensor_data.csv
- ラボ分析データ ⇒ bunsekiti.xlsx
# pandasライブラリをimport
import pandas as pd
# dfという名前のdataframeにcsvファイルを読み込む。
df = pd.read_csv('sensor_data.csv')
# df2という名前のdataframeにexcelファイルを読み込む。
df2 = pd.read_excel('bunsekiti.xlsx')
はい。これだけです。
非常に簡単にデータを読み込むことができました。
ちゃんとデータが読み込まれているか、一応確認しておきましょう。
#始めの5行を表示 df.head()

#初めの5行を表示 df2.head()
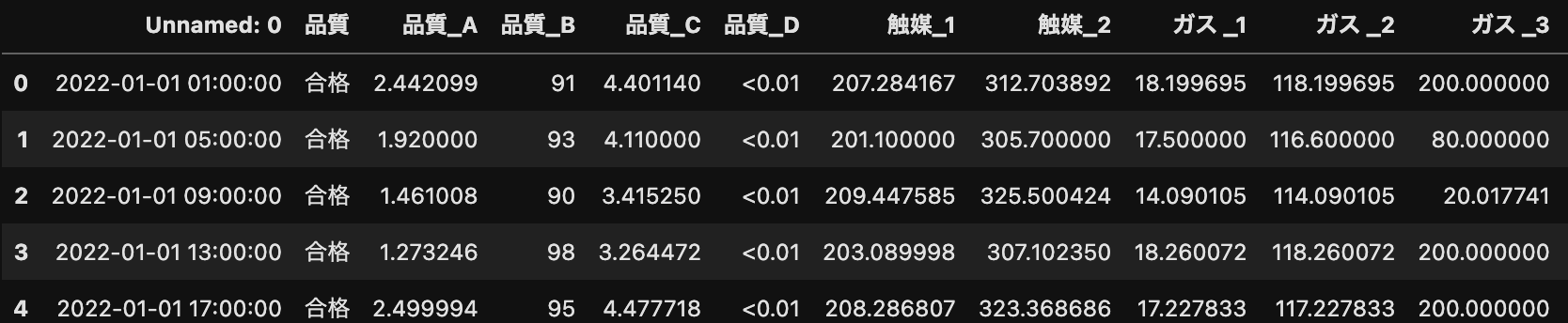
上図のようにデータが読み込めました。
.head()と入力すると、上から5行を表示してくれます。
また、( )内に見たい行数を入力することができますので、5行で少ないときは好きな数字を入力してみて下さい。
もしエラーが出たら、エラー文をコピーしてGoogle検索または、ChatGPTに聞いてみましょう!
絶対パスと相対パス
データを読み込む際は、pythonファイル(.py or .pynbファイル)とデータファイル(csv、excelファイル)を同じフォルダ(ディレクトリ)において下さい。
【参考記事】「ディレクトリ」と「フォルダ」の違いと共通点
もし、pythonファイルとデータファイルが別のフォルダに存在する場合は、データファイルまでのパスを指定する必要があります。
また、パスの指定には絶対パスと相対パスの2種類あります。
基本的には相対パスで指定しますが、下記に絶対パスと相対パスの例を示します。
(1)絶対パスで指定
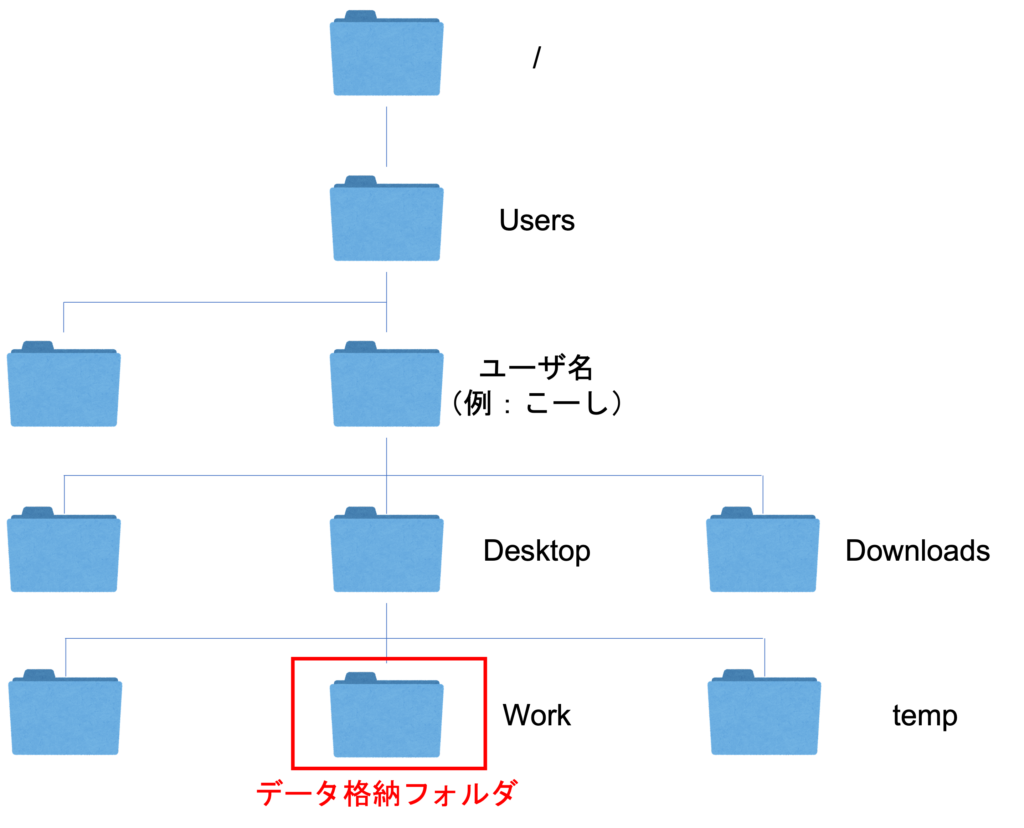
<Windowsの場合>
import pandas as pd
# 絶対パスを用いてファイルを指定する(Windows)。
df = pd.read_csv('C:/Users/ユーザ名/Desktop/work/sensor_data.csv')
<Macの場合>
import pandas as pd
# 絶対パスを用いてファイルを指定する(Mac)。
df = pd.read_csv('/Users/ユーザ名/Desktop/work/sensor_data.csv')
(2)相対パスで指定
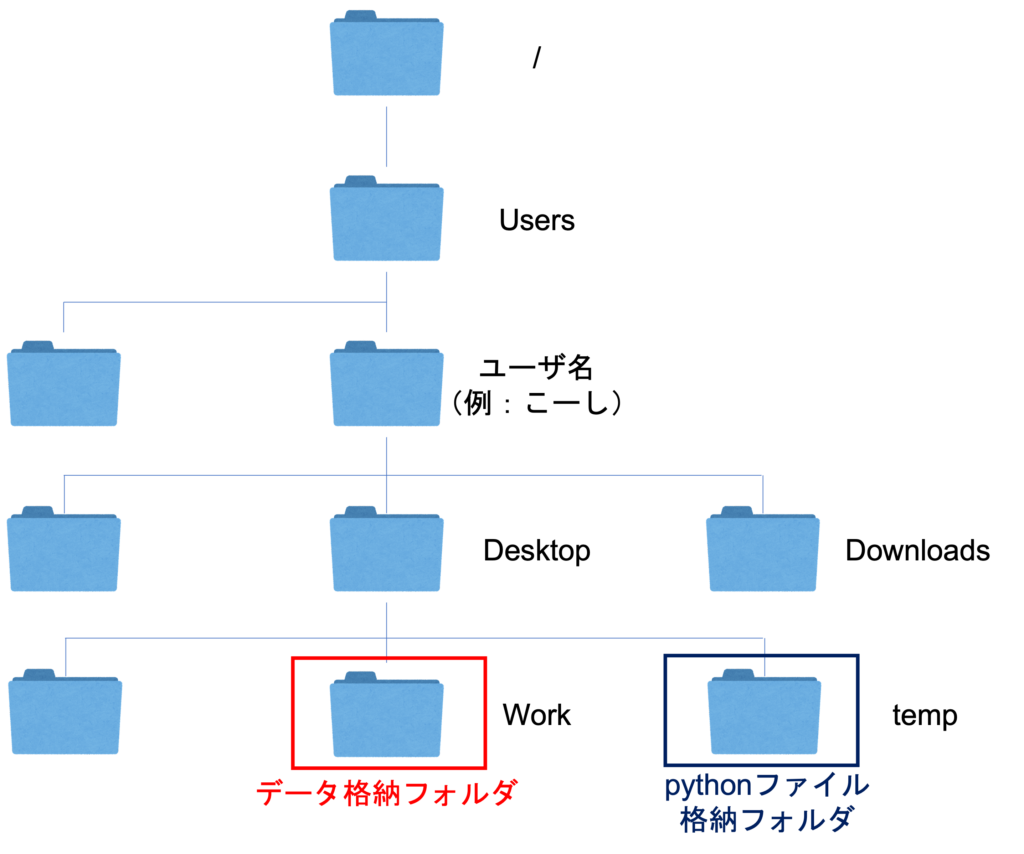
上図では、pythonファイルが格納されているフォルダから見ると、一つ上の階層にあるDesktopフォルダの中のWorkフォルダにデータがあるので、下記のようにファイル名を指定します。
<WindowsとMac共通>
import pandas as pd
# 相対パスを用いてファイルを指定する(WindowsとMac両方)。
df = pd.read_csv('../work/sensor_data.csv')
相対パスは、WindowsとMacで同じように書けます。
相対パスでは、一つ上の階層のフォルダを「 ../ 」のように書くことができます。
もっと詳しく知りたい方は、下記の記事を参考にしてみてください。
【参考記事】【初心者向け】絶対パスと相対パスの違いについて解説
csvファイルに日本語が含まれる場合
csvファイルに日本語(ひらがな・カタカナ・漢字)が含まれる場合、エラーが出ることがあります。
encodingという引数に'shift-jis'を指定すると解決します。
import pandas as pd
# encodingという引数に'shift-jis'を指定する。
df = pd.read_csv('sensor_data.csv', encoding='shift-jis')
これでもエラーが出るなら、日本語を全て半角英数字に変更してみましょう。
indexとheaderを指定

上図のように、1行目にいらない情報が入っている場合を考えましょう。
headerという引数に数字を入力することで、読み込むデータの先頭行を指定することができます。
import pandas as pd
# headerという引数に行数を指定する。
df = pd.read_csv('sensor_data2.csv', header=1)
df.head()
注意ポイント
Pythonでは、数の数え方が0, 1, 2, 3, …と「0から始まる」ことに注意して下さい。
上図の例だと2行目をheaderに指定しますが、入力するのは1です。
また、時系列データの場合indexを時間の列(上図ではA列)に指定します。
pythonでは0から数え始めることに注意して下さい。
import pandas as pd
# index_colという引数に列数を指定する。
df = pd.read_csv('sensor_data2.csv', header=1, index_col=0)
df.head()
index名とcolumns名の変更
上図のデータのindex名とcolumns名を変更してみましょう。
ちなみに、columns名とは「列名」のことです。
ラボ分析データ(bunsekiti.xlsx)のcolumns名は、「品質」、「触媒_1」など日本語表記になっています。
日本語はエラーを引き起こす原因になるので、念のため半角英数字に変更しておきましょう。
import pandas as pd
df2 = pd.read_excel('bunsekiti.xlsx', index_col=0)
# 行数と列数を表示
df2.shape
.shapeと入力すると、例えば(31, 10)のように、(行数, 列数)が表示されます。
よって、列数と同じ数の文字列をリストにしてdf.columnsに代入してみましょう。
# columns_nameというリストに10個、列名を入力 columns_name = ['Q', 'Q_A', 'Q_B', 'Q_C', 'Q_D', 'C_1', 'C_2', 'G_1', 'G_2', 'G_3'] # df2.columnsにcolumns_nameを代入する df2.columns = columns_name
また、現状index名はありません。
df2.index.nameに文字列を代入し、index名を'Time'にしてみましょう。
#index名をTimeにする df2.index.name = 'Time' #一応確認 df2.head()
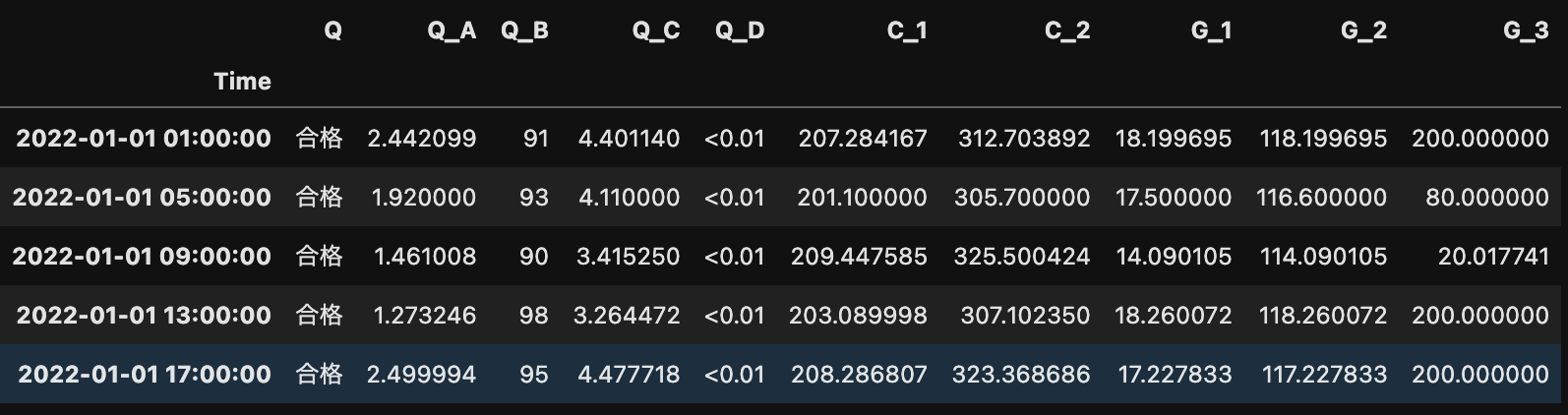
index名とcolumns名を変換したデータは上図の通りです。
時系列データの注意点(データ型)
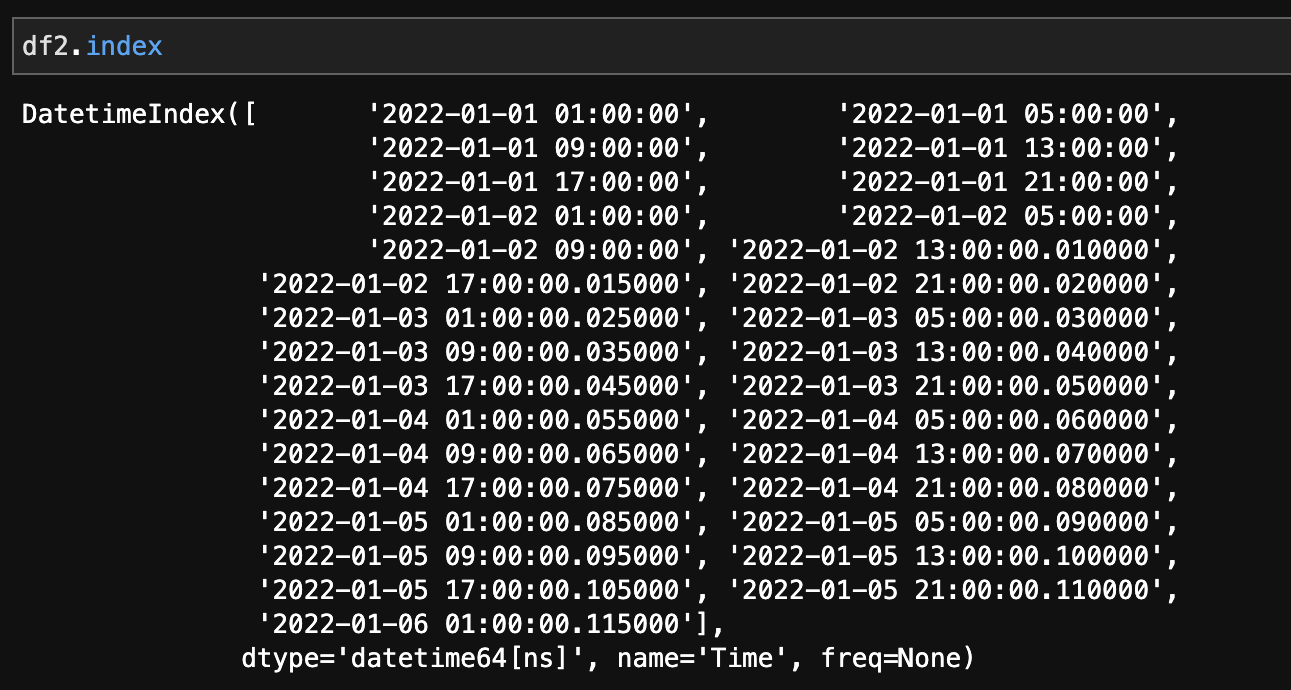
「2022/1/1 0:00」のように、時間を表すデータ列があっても、pythonが時間のデータと認識していない場合があります。
よって、df2.indexと入力し、データ型(dtype)を調べましょう。
下図のように、dtype='datetime64[ns]'と出力されれば問題ありません。
もし、時間を表すデータ型でなかった場合('object'など)は、下記コードでdatetime型に変換しましょう。
# indexのデータをdatetime型に変換 df2.index = pd.to_datetime(df2.index)
自分が扱っているデータの「型」が何なのか把握しておきましょう!
参考文献
現場で使える! pandasデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法 (AI & TECHNOLOGY)
675ページある分厚い本ですので、データの前処理について知りたいことはほとんど書いてあります。
手元にあると頼もしい1冊です。
pythonの勉強方法については、別記事で詳しく解説しています。
-

-
【初心者向け】データサイエンスのためのPython学習方法
続きを見る
