
どうも。こんにちは。
ケミカルエンジニアのこーしです。
本日は、「ラグ特徴量(時間遅れ変数)の相関係数」についてPythonのStreamlitライブラリで可視化しながら解説します。
化学プロセスでは、原料⇒反応器⇒晶析槽⇒固液分離機⇒バッファタンクのような流れで連続的に処理されるため、バッファタンクの液面変動は数時間前の原料供給量の変動が原因だったりします。
そこで、化学プロセスのような時系列データでは、ラグ特徴量(時間遅れ変数)の相関係数をチェックする必要があります。
本記事を読めば、ラグ特徴量(時間遅れ変数)の相関係数を簡単にチェックできるツールを作成できるようになります。
本記事の内容
・最終成果物
・サンプルデータの入手
・時系列トレンドの比較
・散布図と相関係数
・相関係数ヒートマップ
・時間遅れ変数の相関係数チェック
・参考文献
目次
最終成果物
本記事で作成する可視化ツール(ダッシュボード)の動画をXにアップしました。
ブラウザで実際に触ることができるStreamlit Shareにもアップしています(リンク)
また、ソースコードもコチラ(GitHub)に公開しています。
化学プラントの時系列データを解析する際は、時間遅れ(ラグ特徴量)を考慮する必要がある。
例えば、反応器前後のデータでは、反応器の滞留時間分、時間をズラすと良い。
そこで、時間遅れ変数の相関関係を可視化するダッシュボードを作ってみた!
Streamlitなら簡単かも!https://t.co/gACgo3VZN9 pic.twitter.com/C5h6Um5cL6— こーし⚡️ケミカルエンジニア (@mimikousi) July 11, 2024
PythonのStreamlitで、時間遅れ変数(ラグ特徴量)の相関係数を確認するダッシュボードを作成してみた!
可視化した方が、どのくらい時間遅れがありそうか見当つけやすいかな。
ChatGPTにコードを書いてもらったので、コードを書くより、GitHubとStreamlit Sharingにアップする方が難しかった。。 pic.twitter.com/S1sKV9tQnk— こーし⚡️ケミカルエンジニア (@mimikousi) July 12, 2024
サンプルデータの入手
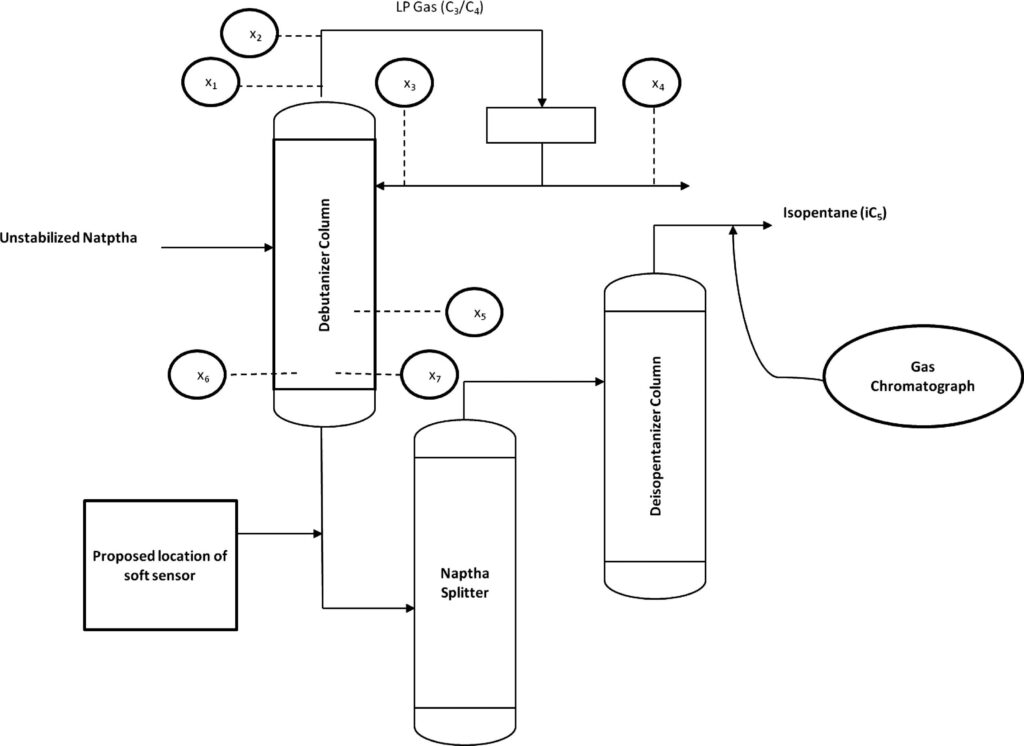
コチラのGitHubページで入手できる「debutanizer_data.csv」を利用します。
脱ブタン塔のプロセスデータであり、プロセスフローは上図の通りです。
説明変数がx1〜x7の7個で、目的変数がyの1個、サンプル数は2394個です。
| 変数名 | 詳細 | 日本語訳 |
|---|---|---|
| x1 | Top Temperature | 塔頂温度 |
| x2 | Top pressure | 塔頂圧力 |
| x3 | Reflux flow | 還流流量 |
| x4 | Flow to next process | 次プロセスへの流量 |
| x5 | 6th tray Temperature | 6段目温度 |
| x6 | Bottom Temperature1 | 塔底温度1 |
| x7 | Bottom Temperature2 | 塔底温度2 |
| y | Butane(C4) content in the debutanizer column bottom | 塔底におけるブタン含有量 |
データの読み込み
「debutanizer_data.csv」と同じフォルダに、「main.py」というファイルを作成しましょう。
下記のコードでライブラリのインポートと、データの読み込みを行います。
ここでは、下記2つのデータの前処理を行っています。
- 時系列データなので、実務データを想定しインデックスに時刻を割り振る(1分間隔)
- 目的変数yの測定時間を考慮し、5分(行)だけデータをずらす
import pandas as pd import numpy as np import scipy as sp import matplotlib.pyplot as plt import matplotlib.dates as mdates import japanize_matplotlib import seaborn as sns sns.set(font='IPAexGothic') import streamlit as st import datetime from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error
#脱ブタン塔のプロセスデータを読み込む
df = pd.read_csv('debutanizer_data.csv', header=0)
#時系列データなので、実務データを想定しindexに時刻を割り当てる
# 開始日時を指定
start_datetime = '2024-01-01 00:00:00'
# DataFrameの長さを取得
n = len(df)
# 日時インデックスを生成(1分間隔)
date_index = pd.date_range(start=start_datetime, periods=n, freq='T')
# DataFrameのインデックスを新しい日時インデックスに設定
df.index = date_index
# 目的変数の測定時間を考慮(5分間)
df['y'] = df['y'].shift(5)
#yがnanとなる期間のデータを削除
df = df.dropna()
時系列トレンドの比較

上図のように、可視化したい変数を2つ選択してトレンドグラフを比較できるようにしましょう。
また、時間遅れ(0〜30分まで)やデータ期間もスライドバーで変更できるようにします。
pythonコードは下記の通りです。
# Streamlitアプリケーションの作成
st.title("時系列データのトレンド比較")
dates = df.index
# 変数の選択
columns = df.columns.tolist()
column1 = st.selectbox("比較する最初の変数を選択してください", columns)
column2 = st.selectbox("比較する2番目の変数を選択してください", columns)
# 時間遅れの選択
lag1 = st.slider("最初の変数の時間遅れを選択してください", min_value=0, max_value=30, value=0)
lag2 = st.slider("2番目の変数の時間遅れを選択してください", min_value=0, max_value=30, value=0)
# 期間選択
start_date = st.slider("開始日", min_value=dates.min().to_pydatetime(), max_value=dates.max().to_pydatetime(), value=dates.min().to_pydatetime())
end_date = st.slider("終了日", min_value=dates.min().to_pydatetime(), max_value=dates.max().to_pydatetime(), value=dates.max().to_pydatetime())
# 選択された期間のデータをフィルタリング
filtered_df = df.loc[start_date:end_date]
# 時間遅れ変数の生成
lagged_column1 = filtered_df[column1].shift(lag1)
lagged_column2 = filtered_df[column2].shift(lag2)
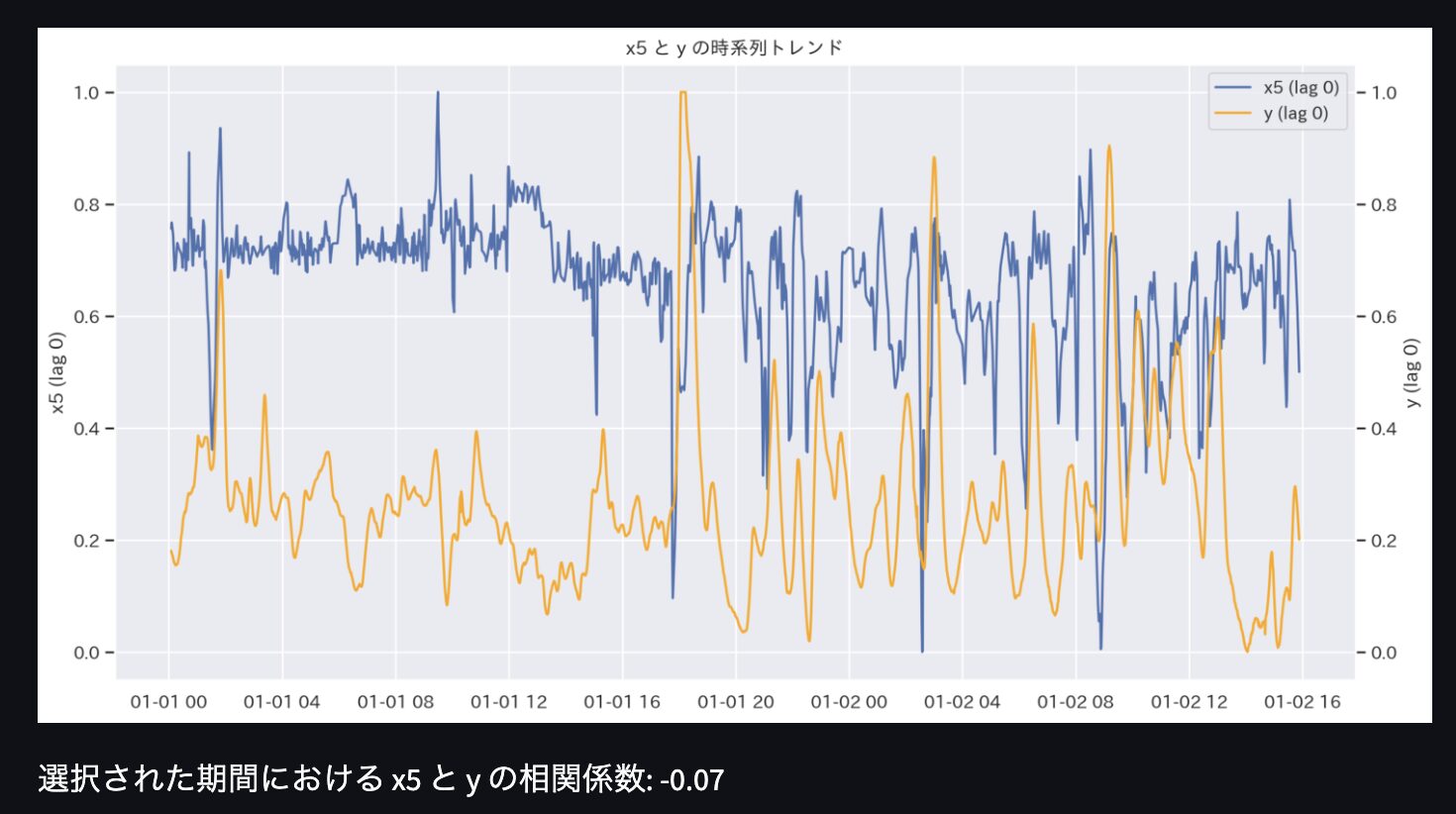
続いて、上図のように2変数を比較するトレンドグラフを作成します。
また、図の下に相関係数が表示されるようにしましょう。
Pythonコードは下記の通りです。
# 時系列トレンドグラフを作成
fig, ax1 = plt.subplots(figsize=(14, 7))
ax2 = ax1.twinx()
ax1.plot(filtered_df.index, lagged_column1, label=f'{column1} (lag {lag1})')
ax2.plot(filtered_df.index, lagged_column2, label=f'{column2} (lag {lag2})', color='orange')
ax1.set_title(f'{column1} と {column2} の時系列トレンド')
#ax1.set_xlabel('Date')
ax1.set_ylabel(f'{column1} (lag {lag1})')
ax2.set_ylabel(f'{column2} (lag {lag2})')
plt.grid(False)
h1, l1 = ax1.get_legend_handles_labels()
h2, l2 = ax2.get_legend_handles_labels()
ax1.legend(h1+h2, l1+l2, loc='best')
# グラフをStreamlitに表示
st.pyplot(fig)
# 相関係数を計算
correlation = lagged_column1.corr(lagged_column2)
# 相関係数を表示
st.write(f"選択された期間における {column1} と {column2} の相関係数: {correlation:.2f}")
見たい変数を入れ替えたり、時間遅れの時間を変更したり、データ期間を変更しながら、トレンドデータを比較できるようになりました。
散布図と相関係数
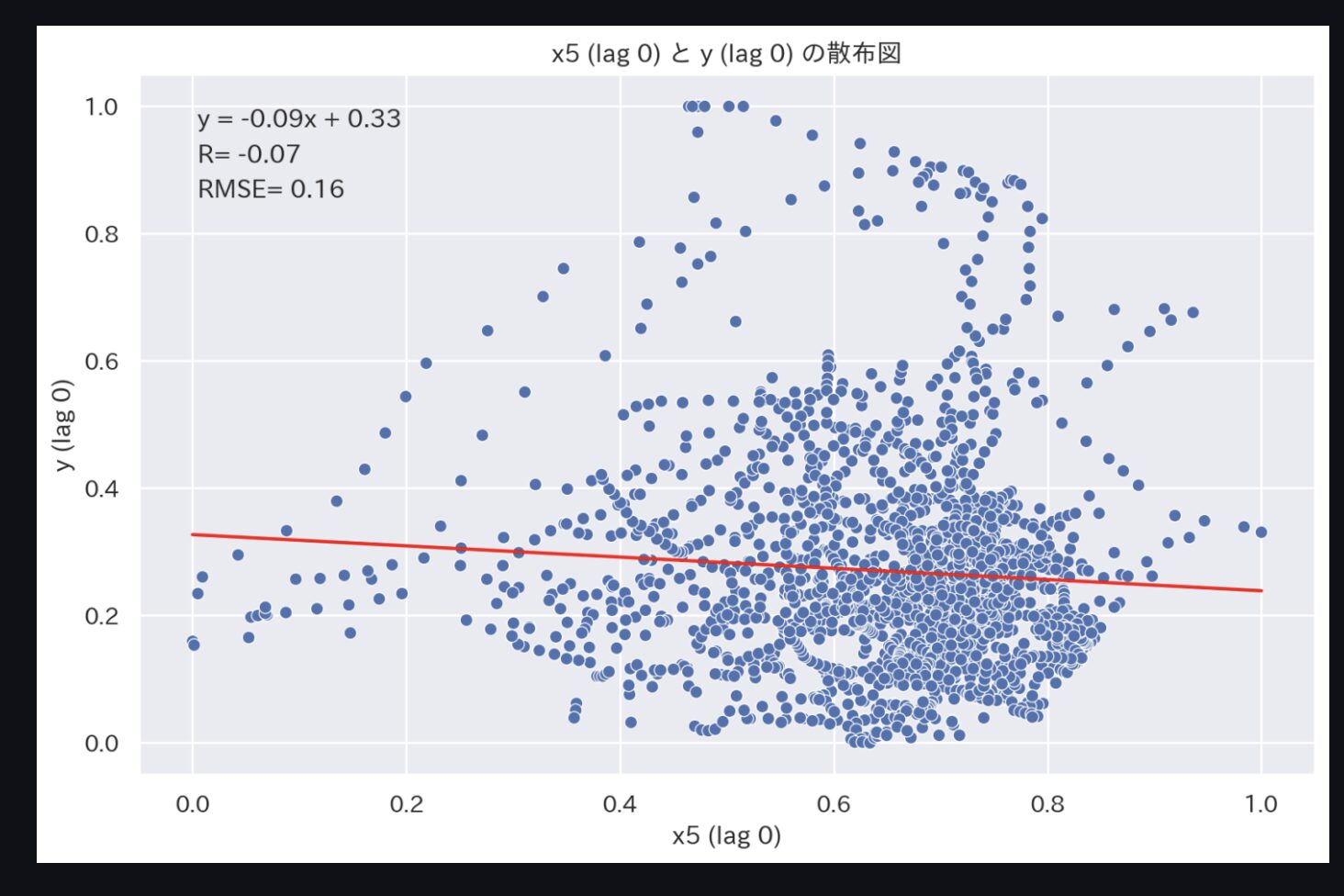
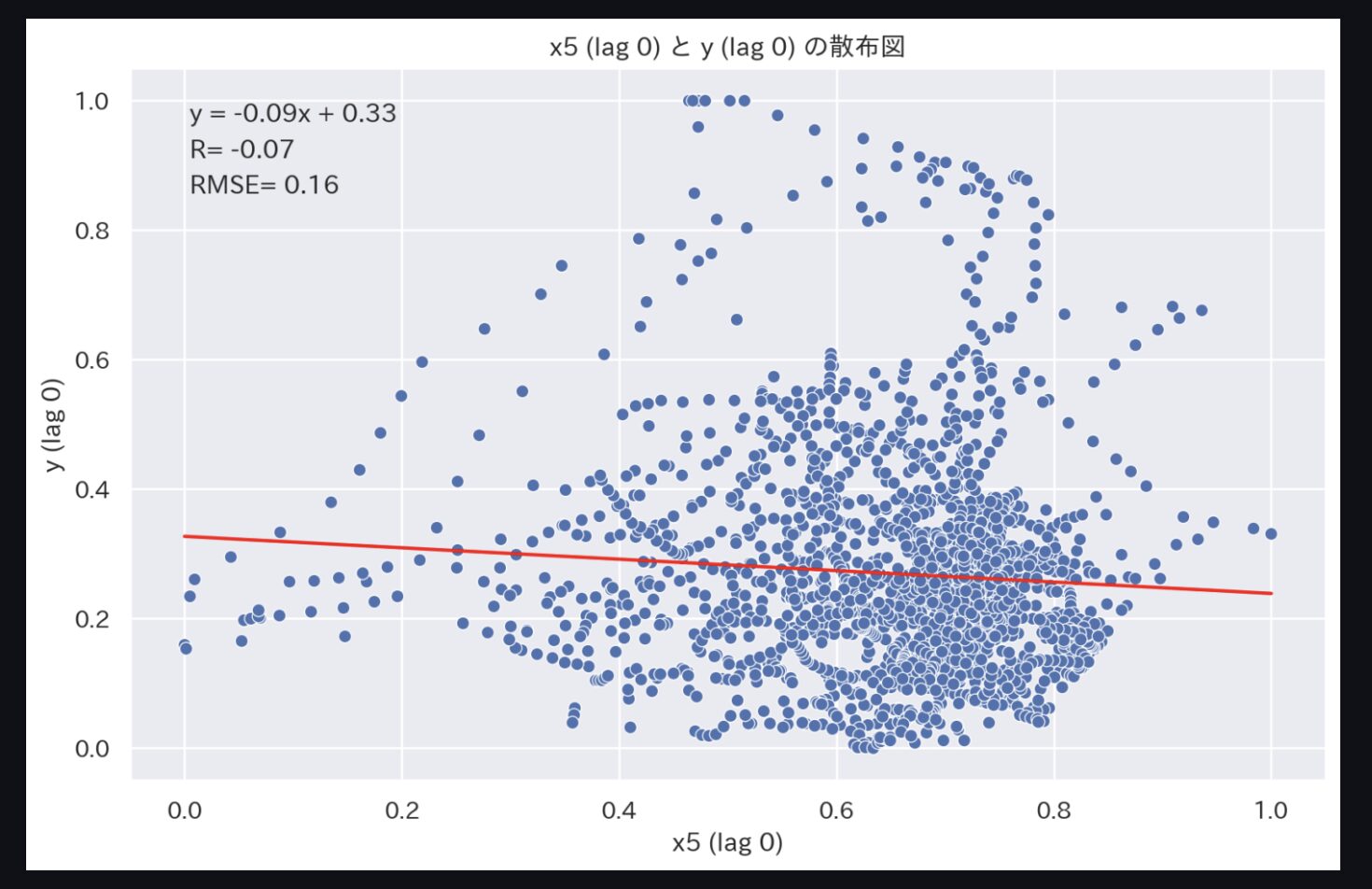
続いて、上記のような散布図を作成しましょう。
トレンドグラフでは、2変数の関係性はわかりにくいので散布図で確認します。
pythonコードは下記の通りです。
# データの対応する行が存在しないデータを除外
lagged_df = pd.DataFrame({f'{column1}_lag{lag1}': lagged_column1, f'{column2}_lag{lag2}': lagged_column2}).dropna()
# 散布図と線形近似直線を作成
fig, ax = plt.subplots(figsize=(10, 6))
sns.scatterplot(x=lagged_df[f'{column1}_lag{lag1}'], y=lagged_df[f'{column2}_lag{lag2}'], ax=ax)
ax.set_title(f'{column1} (lag {lag1}) と {column2} (lag {lag2}) の散布図')
ax.set_xlabel(f'{column1} (lag {lag1})')
ax.set_ylabel(f'{column2} (lag {lag2})')
# 線形回帰モデルを作成
model = LinearRegression()
X = lagged_df[f'{column1}_lag{lag1}'].values.reshape(-1, 1)
y = lagged_df[f'{column2}_lag{lag2}'].values.reshape(-1, 1)
model.fit(X, y)
line_x = np.linspace(X.min(), X.max(), 100)
line_y = model.predict(line_x.reshape(-1, 1))
# 近似直線をプロット
ax.plot(line_x, line_y, color='red', label='Linear Fit')
# 近似直線の式と相関係数を図に追加
slope = model.coef_[0][0]
intercept = model.intercept_[0]
standard_error = np.sqrt(mean_squared_error(y, model.predict(X)))
ax.text(0.05, 0.95, f'y = {slope:.2f}x + {intercept:.2f}', transform=ax.transAxes, fontsize=12, verticalalignment='top')
ax.text(0.05, 0.90, f'R= {correlation:.2f}', transform=ax.transAxes, fontsize=12, verticalalignment='top')
ax.text(0.05, 0.85, f'RMSE= {standard_error:.2f}', transform=ax.transAxes, fontsize=12, verticalalignment='top')
# 凡例を追加
#ax.legend()
# グラフをStreamlitに表示
st.pyplot(fig)
ここまで書けたら、terminalもしくはコマンドプロンプトで、「Streamlit run main.py」を実行しましょう。
ブラウザが開き、Webアプリケーションが作成できると思います。
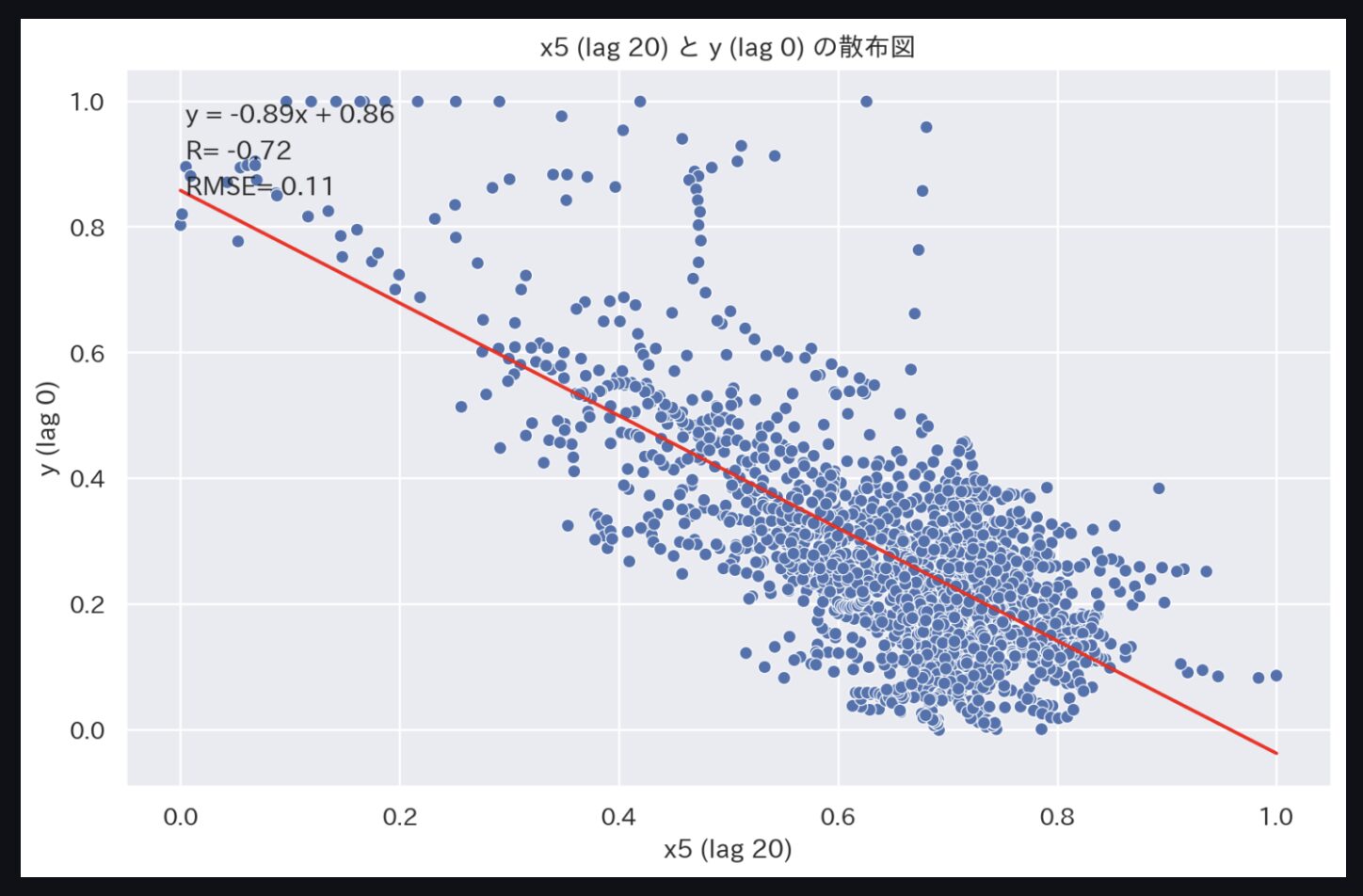
無事Webアプリ(ダッシュボード)が作成できたら、時間遅れの時間を変更しつつ散布図をチェックしてみましょう。
特に顕著なのは、'x5'と'y'です。
時間遅れが0分(元データ)だと相関係数-0.07ですが、時間遅れを20分にすると相関係数-0.72となります。
時系列データの相関チェックツール
データの読み込み
続いて、別のpythonファイルで相関関係チェックツールを作成しましょう。
「debutanizer_data.csv」と同じフォルダに、「correlation.py」というファイルを作成します。
先ほどと同様、ライブラリのインポートとデータの読み込みを行います。
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
import japanize_matplotlib
import seaborn as sns
sns.set(font='IPAexGothic')
import streamlit as st
import datetime
#脱ブタン塔のプロセスデータを読み込む
df = pd.read_csv('debutanizer_data.csv', header=0)
#時系列データなので、実務データを想定しindexに時刻を割り当てる
# 開始日時を指定
start_datetime = '2024-01-01 00:00:00'
# DataFrameの長さを取得
n = len(df)
# 日時インデックスを生成(1分間隔)
date_index = pd.date_range(start=start_datetime, periods=n, freq='T')
# DataFrameのインデックスを新しい日時インデックスに設定
df.index = date_index
# 目的変数の測定時間を考慮(5分間)
df['y'] = df['y'].shift(5)
#yがnanとなる期間のデータを削除
df = df.dropna()
dates = df.index
相関係数ヒートマップ
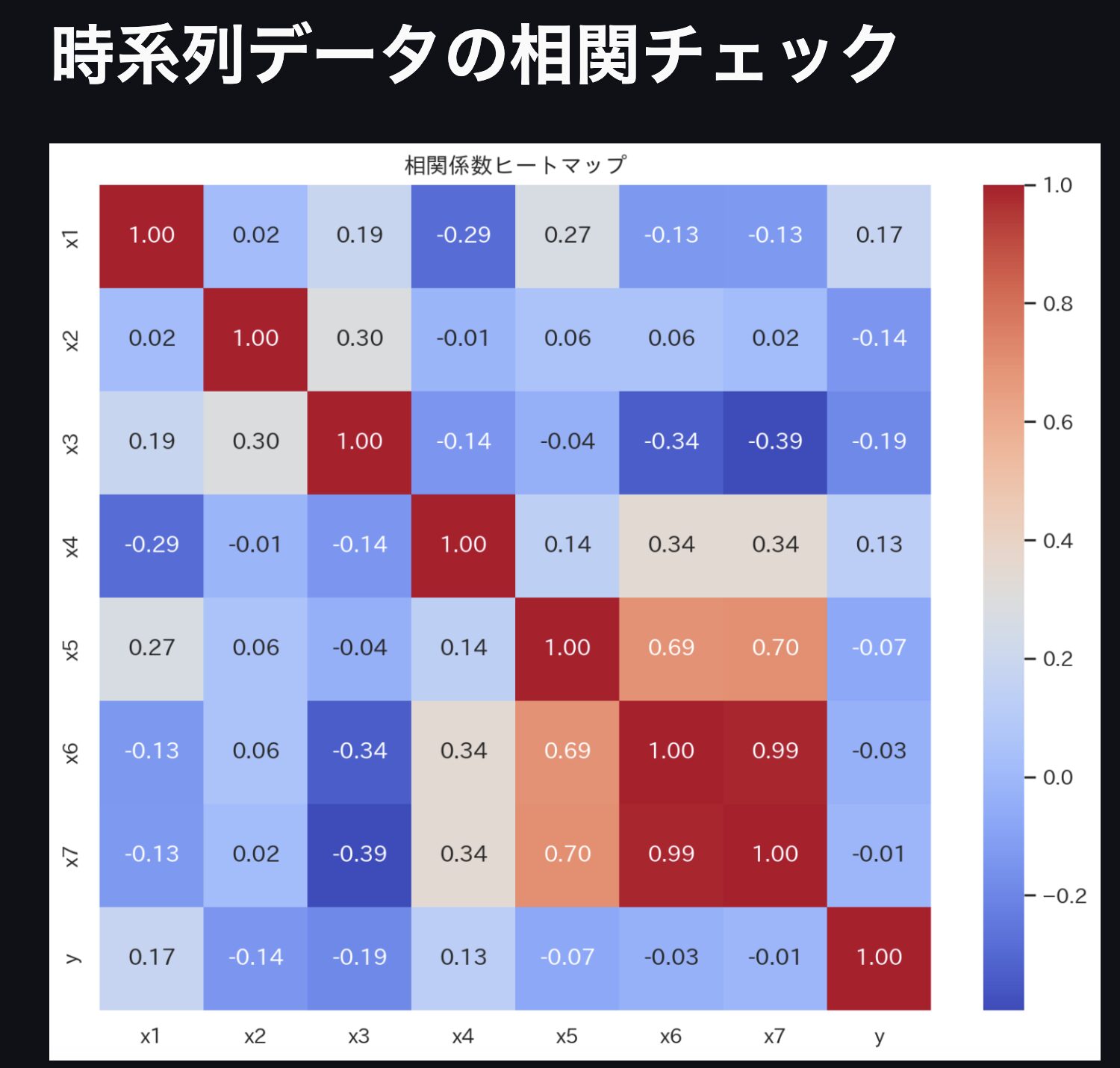
念のため、各変数の相関関係をヒートマップで確認します(必要かわかりませんが、おまじないです)
pythonコードは下記の通りです。
# Streamlitアプリケーションの作成
st.title("時系列データの相関チェック")
# 全カラム対全カラムの相関係数のヒートマップを作成
corr_matrix = df.corr()
fig, ax = plt.subplots(figsize=(10, 8))
sns.heatmap(corr_matrix, annot=True, fmt=".2f", cmap='coolwarm', ax=ax)
ax.set_title('相関係数ヒートマップ')
st.pyplot(fig)
時間遅れ変数の相関係数チェック
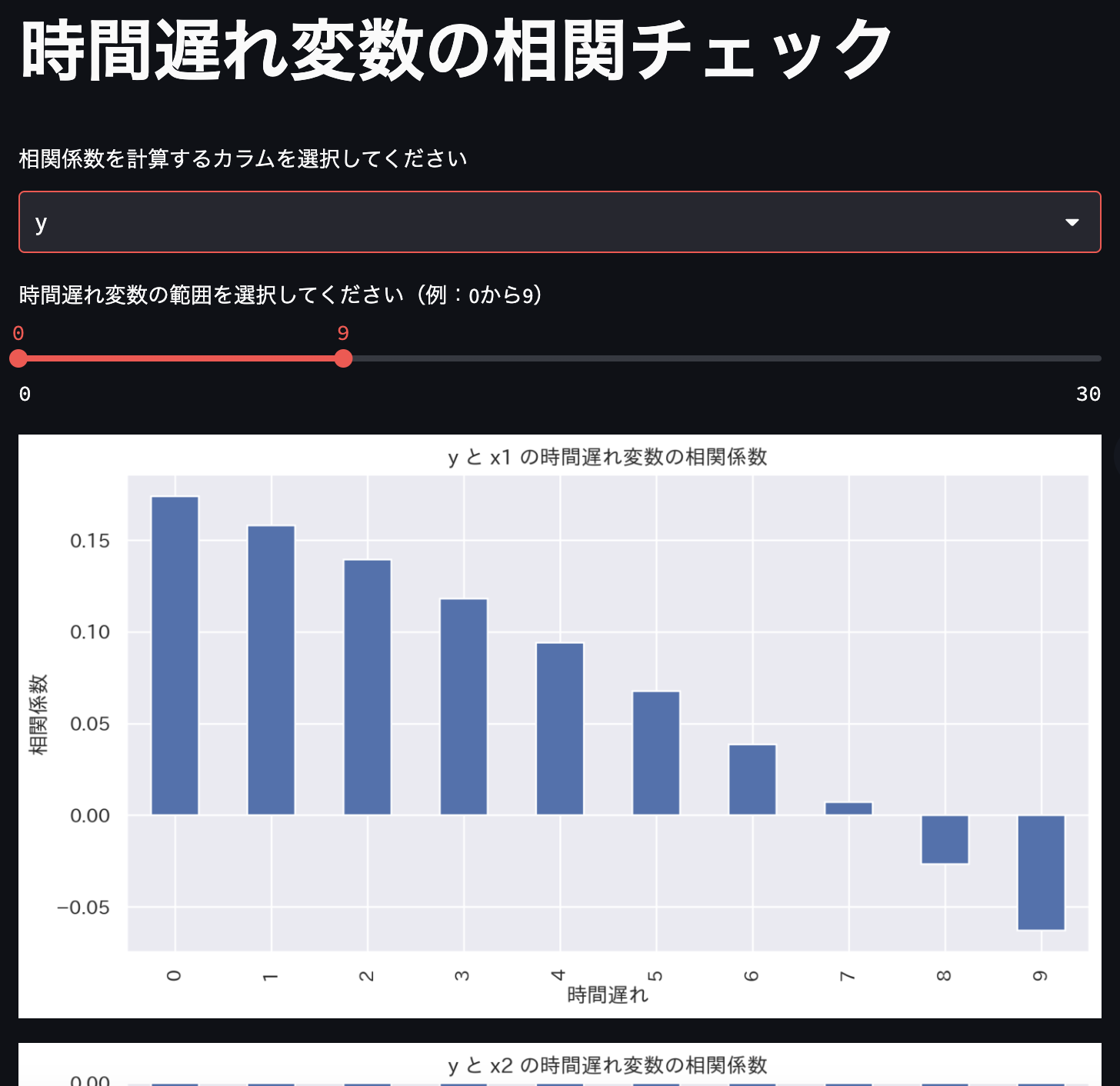
上図のように、着目する変数を選択し、見たい時間遅れ変数の相関係数を棒グラフで示します。
pythonコードは下記の通りです。
# Streamlitアプリケーションの作成
st.title("時間遅れ変数の相関チェック")
# カラム選択
columns = df.columns.tolist()
target_column = st.selectbox("相関係数を計算するカラムを選択してください", columns)
delay_range = st.slider("時間遅れ変数の範囲を選択してください(例:0から9)", min_value=0, max_value=30, value=(0, 9))
# 遅れ変数の作成と相関係数の計算
correlations = {}
for col in columns:
if col != target_column:
correlations[col] = []
for lag in range(delay_range[0], delay_range[1] + 1):
df[f'{col}_delay_{lag}'] = df[col].shift(lag)
df_lagged = df.dropna()
for lag in range(delay_range[0], delay_range[1] + 1):
correlation = df_lagged[target_column].corr(df_lagged[f'{col}_delay_{lag}'])
correlations[col].append((lag, correlation))
# カラムごとにグラフを作成
for col in correlations:
lagged_df = pd.DataFrame(correlations[col], columns=['Lag', 'Correlation'])
fig, ax = plt.subplots(figsize=(10, 5))
lagged_df.plot(kind='bar', x='Lag', y='Correlation', ax=ax, legend=False)
ax.set_title(f'{target_column} と {col} の時間遅れ変数の相関係数')
ax.set_ylabel('相関係数')
ax.set_xlabel('時間遅れ')
# グラフをStreamlitに表示
st.pyplot(fig)
ここまで書けたら、terminalもしくはコマンドプロンプトで、「Streamlit run correlation.py」を実行しましょう。
ブラウザが開き、Webアプリケーションが作成できると思います。
一例として、'x5'に着目して見てみましょう。
0〜9分までの時間遅れの相関係数は下図の通りです。
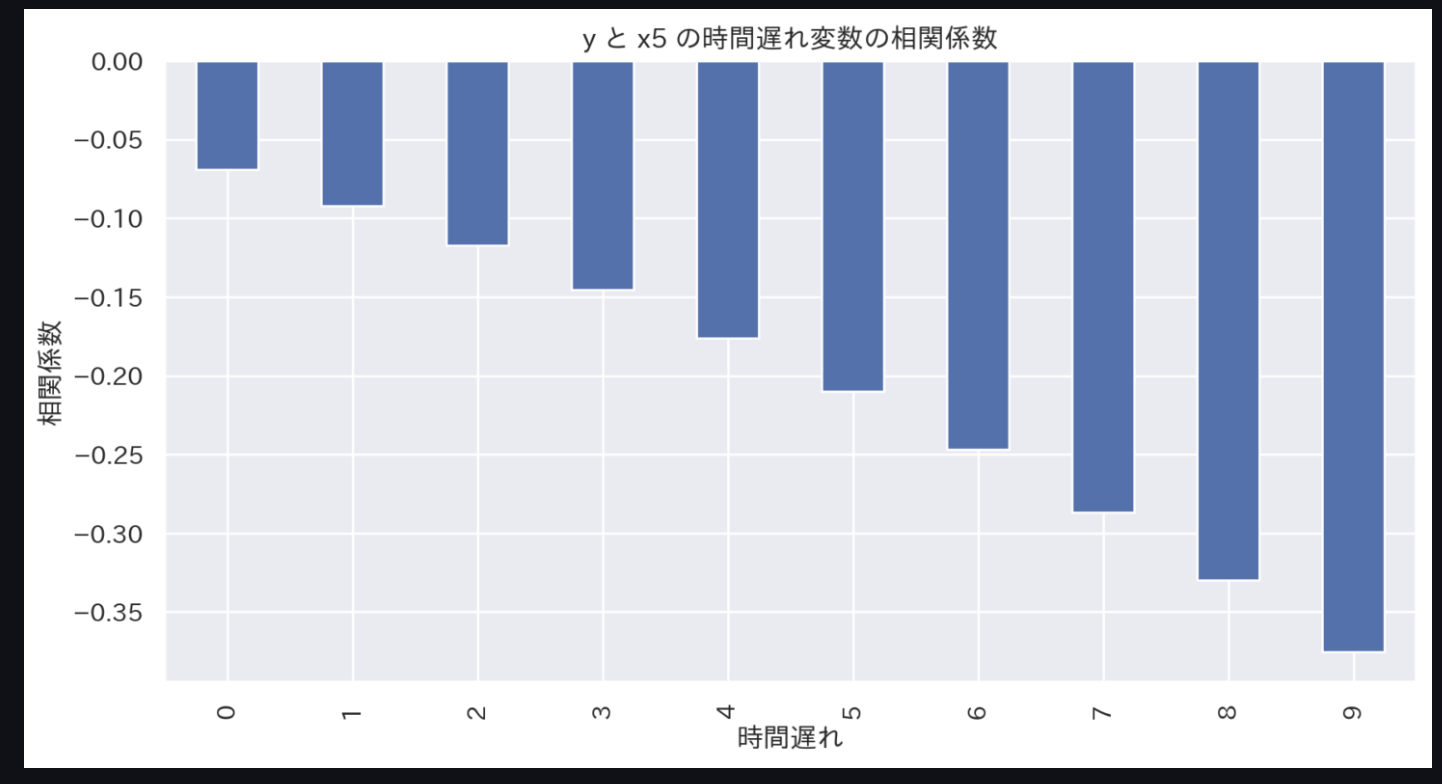
時間遅れを大きくするほど、相関係数(の絶対値)が大きくなっていきます。
もっと時間遅れを大きくしたらどうなるでしょうか。
0〜25分までの時間遅れの相関係数は下図の通りです。
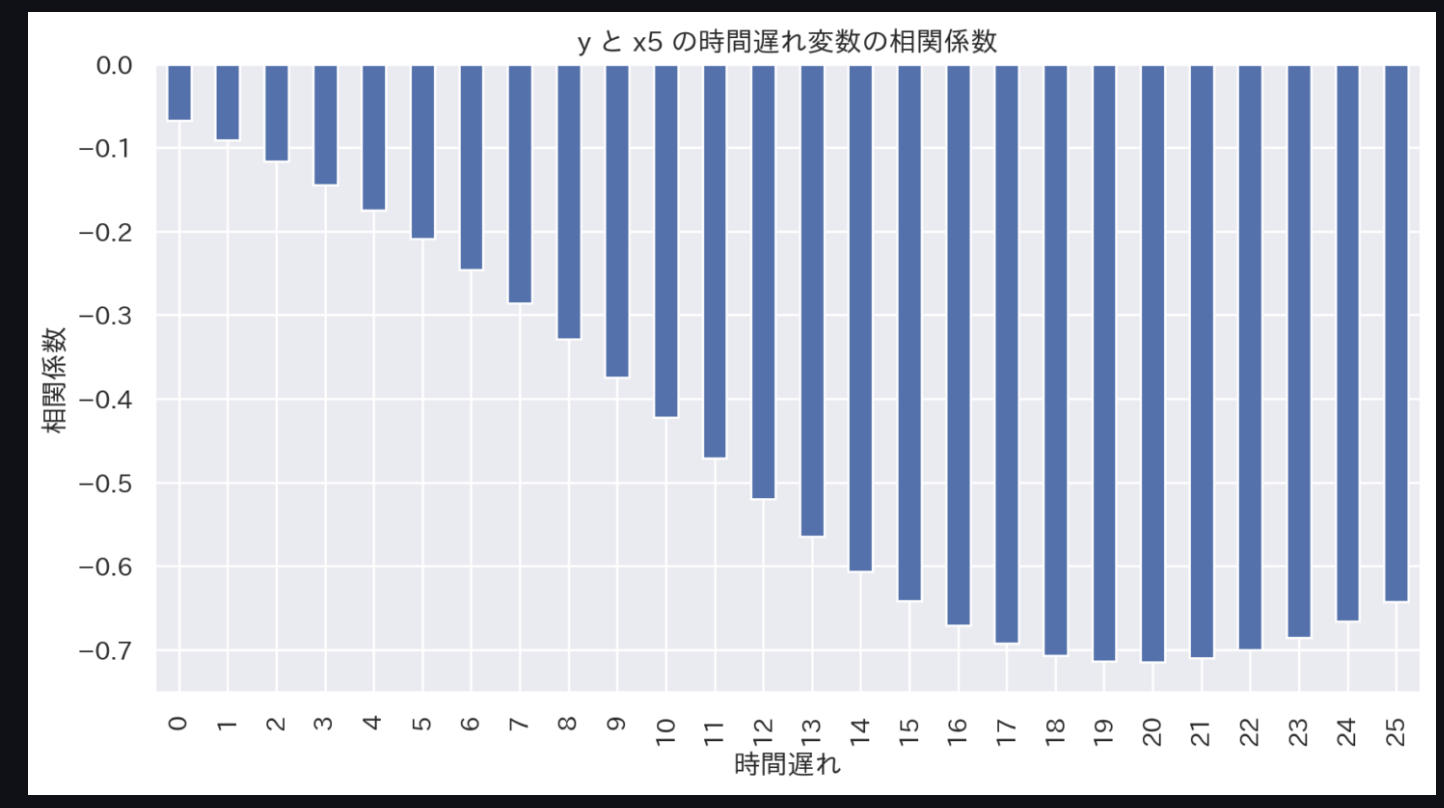
時間遅れ20分で相関係数が頭打ちになりました。
このように、化学プロセスなどの時系列データでは、変数毎に時間遅れを考慮することでデータの特徴を正しく捉えることができるようになります。
ぜひ参考にしてみてください。
参考文献
ラグ特徴量(時間遅れ変数)について簡単に解説してくれています。
Streamlit Shareにアップする方法は下記の記事を参考にしました。
GitHubと連携することで、とても簡単にStreamlit Shareに公開できました。
【Python】Streamlit Sharingで簡単・爆速でWebページをデプロイする!
Streamlitのバージョン1.10.0以降は、マルチページアプリケーションが簡単に作成できるようになりました(サイドバーに別ページを表示)
本記事では、マルチページアプリケーションの方法は紹介していませんが、とても簡単なので興味ある方は下記記事を参考にしてみてください。