
どうも。こんにちは。
ケミカルエンジニアのこーしです。
本日は、pandasによるデータフレームの結合について解説します。
現場のデータ解析では、異なるデータを一つのデータセットに結合する機会が多々あります。
しかし、初心者のうちはどの関数を使うべきかわかりにくいと思います。
そこで本記事では、初心者にもわかりやすいよう図で解説しましたので、ぜひ参考にしてみてください。
本記事の内容
・結合に使う関数(concat,merge)
・データ結合のイメージ
・内部結合と外部結合
この記事を書いた人

こーし(@mimikousi)
目次
データフレームの結合に使う関数(concat,merge)
データフレームの結合に使う関数は、基本的にconcatとmergeの2つです。
| No. | 関数 | 引数 | 使い方 |
| ① | concat | axis=0 | データを縦(列)方向に結合する |
| ② | axis=1 | データを横(行)方向に結合する | |
| ③ | merge | on='key' | 共通のデータ(key)を元に結合する |
ちなみに、データフレーム(DataFrame)とは表形式でデータを表すpandasの「オブジェクト」のことです。
データ結合のイメージ
それでは具体的にデータ結合のイメージを見ていきましょう。
書籍等ではあまり触れられていない時系列データを例に挙げてみました。
①データを縦(列)方向に結合
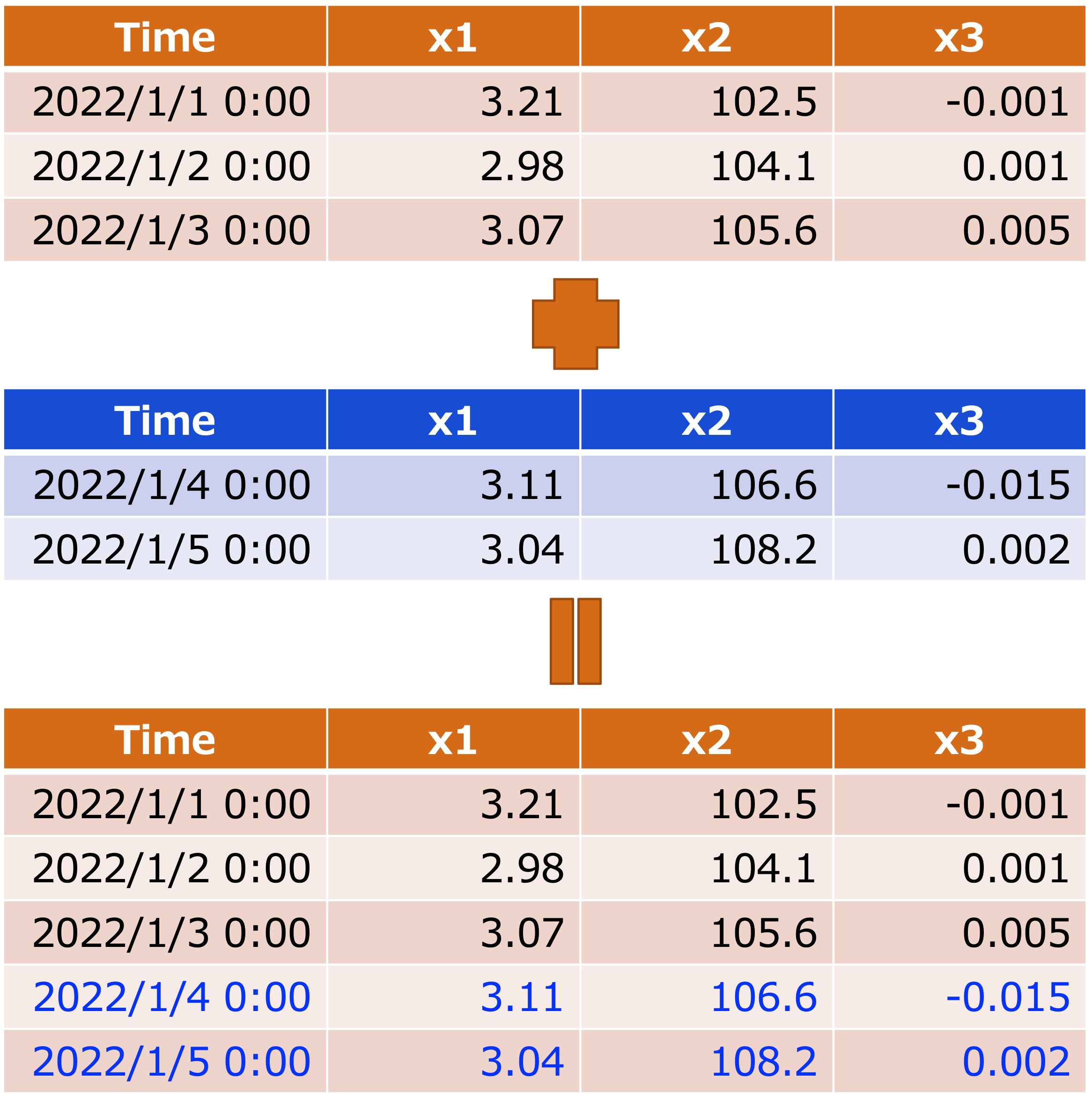
上図のように、実務においてデータを縦(列)方向に結合するケースは下記の通りです。
縦(列)方向に結合するケース
- 時系列データの最新値を加えるとき
- 実験回数を増やしたとき(N数を増やしたとき)
など
pythonのコードは下記の通りです。
import pandas as pd
df1 = pd.DataFrame({
'x1':[3.21, 2.98, 3.07],
'x2':[102.5, 104.1, 105.6],
'x3':[-0.001, 0.001, 0.005]
})
df1.index = ['2022/1/1 0:00', '2022/1/2 0:00', '2022/1/3 0:00']
df1.index.name = 'Time'
print(df1)
df2 = pd.DataFrame({
'x1':[3.11, 3.04],
'x2':[106.6, 108.2],
'x3':[-0.015, 0.002]
})
df2.index = ['2022/1/4 0:00', '2022/1/5 0:00']
df2.index.name = 'Time'
print(df2)
#df1とdf2を縦方向に結合
df3 = pd.concat([df1, df2], axis=0)
print(df3)
pd.concat()で結合したいデータフレーム(ここではdf1, df2)をリスト[ ]の形で指定することで結合できます。
axis引数は、データ結合の方向を指定でき、axis=0だと、列(縦)方向にデータフレームを結合します。
②データを横(行)方向に結合
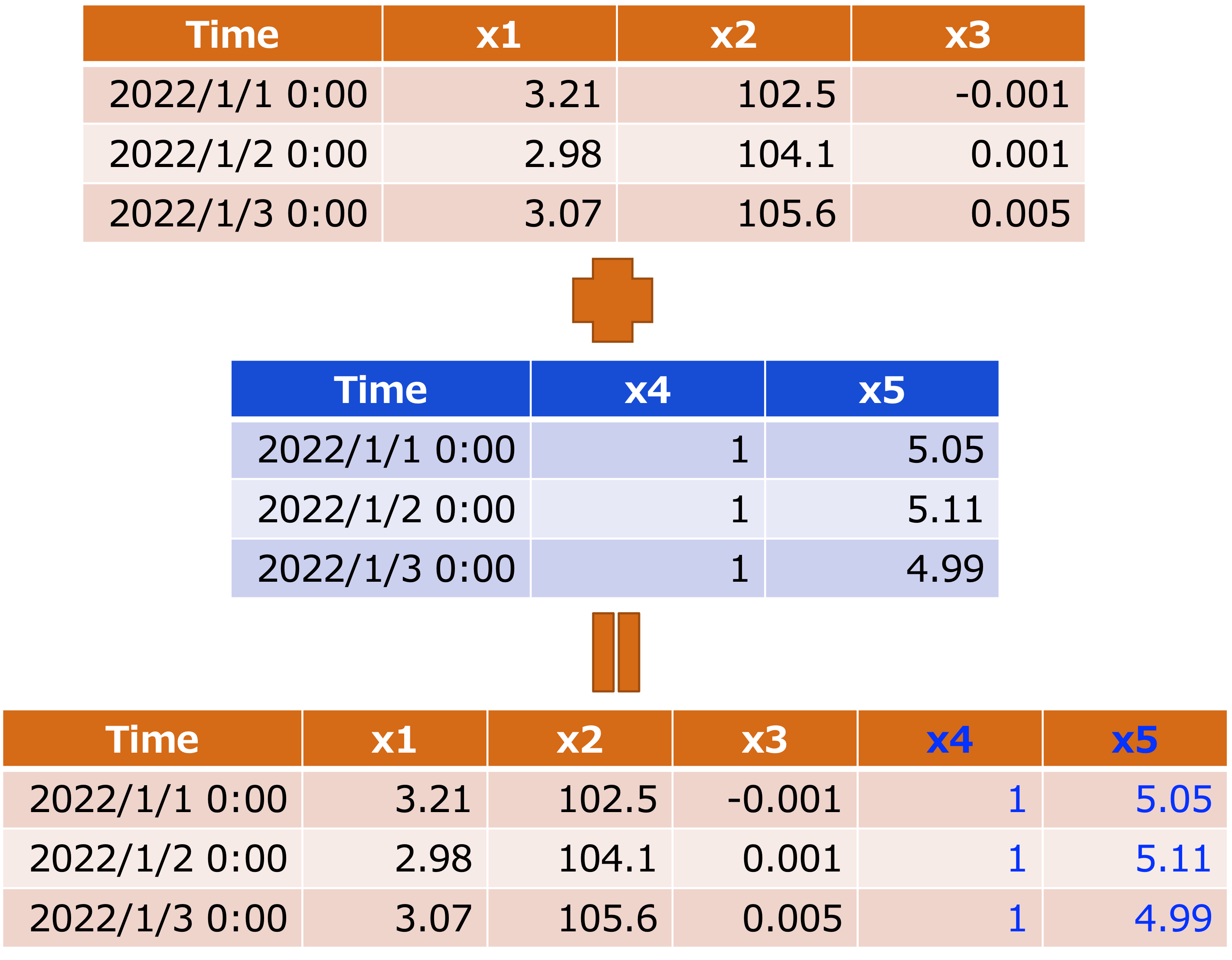
上図のように、実務においてデータを横(行)方向に結合するケースは下記の通りです。
横(行)方向に結合するケース
- 別のデータセットを追加するとき
- 交差項や2乗項など新たな変数を追加するとき
など
pythonコードは下記の通りです。
import pandas as pd
df1 = pd.DataFrame({
'x1':[3.21, 2.98, 3.07],
'x2':[102.5, 104.1, 105.6],
'x3':[-0.001, 0.001, 0.005]
})
df1.index = ['2022/1/1 0:00', '2022/1/2 0:00', '2022/1/3 0:00']
df1.index.name = 'Time'
print(df1)
df2 = pd.DataFrame({
'x4':[1, 1, 1],
'x5':[5.05, 5.11, 4.99]
})
df2.index = ['2022/1/1 0:00', '2022/1/2 0:00', '2022/1/3 0:00']
df2.index.name = 'Time'
print(df2)
#df1とdf2を横方向に結合
df3 = pd.concat([df1, df2], axis=1)
print(df3)
縦方向の結合と同様に、pd.concat()で結合したいデータフレーム(ここではdf1, df2)をリスト[ ]の形で指定することで結合できます。
axis引数は、データ結合の方向を指定でき、axis=1だと、行(横)方向にデータフレームを結合します。
③共通のデータ(key)を元に結合
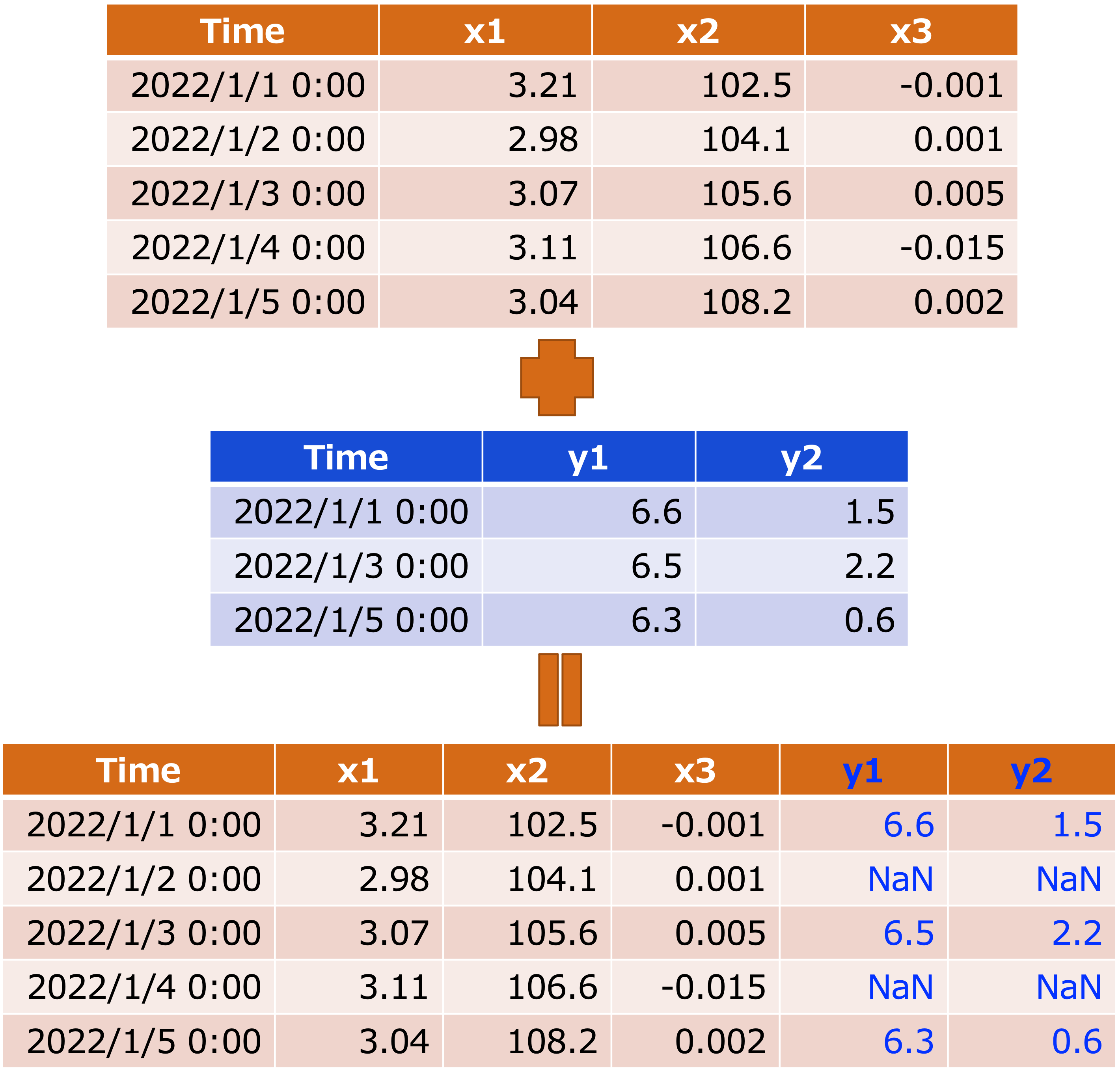
上図のように、実務において共通のデータ(key)を元に結合するケースは下記の通りです。
共通データを元に結合するケース
- 共通の「データ列」を元に結合したいとき
- 異なる時系列データを時刻(key)で結合したいとき
など
pythonコードは下記の通りです。
import pandas as pd
df1 = pd.DataFrame({
'x1':[3.21, 2.98, 3.07, 3.11, 3.04],
'x2':[102.5, 104.1, 105.6, 106.6, 108.2],
'x3':[-0.001, 0.001, 0.005, -0.015, 0.002]
})
df1.index = ['2022/1/1 0:00', '2022/1/2 0:00', '2022/1/3 0:00', '2022/1/4 0:00', '2022/1/5 0:00']
df1.index.name = 'Time'
print(df1)
df2 = pd.DataFrame({
'y1':[6.6, 6.5, 6.3],
'y2':[1.5, 2.2, 0.6]
})
df2.index = ['2022/1/1 0:00', '2022/1/3 0:00', '2022/1/5 0:00']
df2.index.name = 'Time'
print(df2)
#df1とdf2を'Time'(key)を元に結合
df3 = pd.merge(df1, df2, on='Time', how='outer')
print(df3)
on引数にkeyとなるデータ列の「カラム名」を指定します。
上記の例だと、カラム名'Time'をkeyに指定しています(本ケースだとindex名でもあります)。
また、how引数に'inner'もしくは、'outer'を指定してデータの結合方法を決めます。
'inner'は「内部結合」、'outer'は「外部結合」を示しています。
注意ポイント
pd.concat()では、結合したいデータフレームをリスト[ ]の形で指定しましたが、pd.merge()ではリストにする必要はありません。
内部結合と外部結合
 データ結合の方法として、「内部結合」と「外部結合」があります。
データ結合の方法として、「内部結合」と「外部結合」があります。
内部結合では、連結するデータ列の中で一致したデータのみを取得します。
一方、外部結合では連結するデータ列の全てのデータを採用しますが、一致しないデータにはNaNが代入されます。
それでは、具体的なデータを用いて、内部結合と外部結合の違いを見てみましょう。
まず、結合するデータフレームを2つ用意します(df1, df2)。
import pandas as pd
#df1とdf2を用意
df1 = pd.DataFrame({
'x1':[3.21, 2.98, 3.07, 3.11, 3.04],
'x2':[102.5, 104.1, 105.6, 106.6, 108.2],
'x3':[-0.001, 0.001, 0.005, -0.015, 0.002]
})
df1.index = ['2022/1/1 0:00', '2022/1/2 0:00', '2022/1/3 0:00', '2022/1/4 0:00', '2022/1/5 0:00']
df1.index.name = 'Time'
print(df1)
df2 = pd.DataFrame({
'y1':[6.6, 6.5, 6.3],
'y2':[1.5, 2.2, 0.6]
})
df2.index = ['2022/1/1 0:00', '2022/1/3 0:00', '2022/1/5 0:00']
df2.index.name = 'Time'
print(df2)
df1
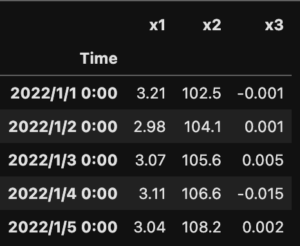
df2
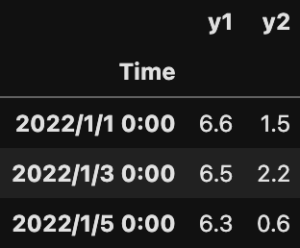
df1とdf2で、共通のデータ列は'Time'列だけです。
'Time'列の中でも、共通部分は2022/1/1 0:00、2022/1/3 0:00、2022/1/5 0:00のデータのみです。
pd.mergeの場合(how引数)
まず、pd.mergeの場合の内部結合/外部結合を見てみましょう。
how引数に、'innner'か'outer'を指定します。
注意ポイント
how引数のデフォルトは、'inner'です。
何も指定しないときは、「内部結合」になります。
内部結合
df3 = pd.merge(df1, df2, on='Time',how='inner') print(df3)
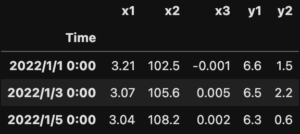
df1とdf2のkey('Time')で、共通部分の2022/1/1 0:00、2022/1/3 0:00、2022/1/5 0:00のデータのみが取得できました。
外部結合
df3 = pd.merge(df1, df2, on='Time',how='outer') print(df3)
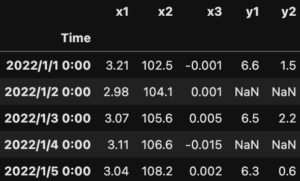
df1とdf2の共通のデータ列('Time')をすべて取得しますが、df2には2022/1/2 0:00、2022/1/4 0:00のデータが無いため、NaNが代入されています。
pd.concatの場合(join引数)
実は、pd.concatの場合でも、join引数に’innner'か'outer'を指定することで内部結合/外部結合を変更することができます。
注意ポイント
join引数のデフォルトは、'outer'です。
何も指定しないときは「外部結合」になります。
merge関数のデフォルトは「内部結合」でしたので、mergeと異なることを覚えておきましょう!
内部結合
df3 = pd.concat([df1, df2], axis=1, join='inner') print(df3)
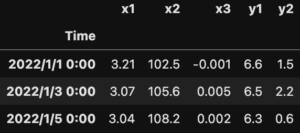
df1とdf2で共通データ列は、'Time'だけですので横(行)方向に結合するaxis=1を指定しています。
結果、mergeの内部結合とまったく同じ結果になりました。
外部結合
df3 = pd.concat([df1, df2], axis=1, join='outer') print(df3)
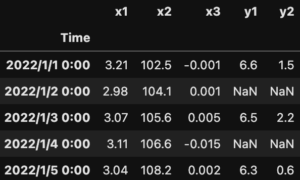
外部結合の場合も、内部結合と同様にmergeとまったく同じ結果になりました。
参考文献
現場で使える! pandasデータ前処理入門 機械学習・データサイエンスで役立つ前処理手法 (AI & TECHNOLOGY)
pandasによるデータの前処理と言えばこの1冊で間違いないでしょう。
675ページある分厚い本ですので、データの前処理について知りたいことはほとんど書いてあります。
手元にあると頼もしい1冊ですね。
pythonの勉強方法については、別記事で詳しく解説しています。
-

-
【初心者向け】データサイエンスのためのPython学習方法
続きを見る
