
どうも。こんにちは。
ケミカルエンジニアのこーしです。
本日は、「プロセスデータの特徴量エンジニアリング」についてわかりやすく解説します。
製造業では、品質管理やプロセス改善のために、様々なプロセスデータを収集しています。
しかし、そのままでは分析に使えない場合が多く、そこで必要なのが「特徴量エンジニアリング」です。
本記事では、pythonを使ってプロセスデータに特有の特徴量を作り出す手段として、時間遅れ変数(ラグ特徴量)、二乗項、交差項の作成方法を紹介します。
これらの特徴量は、プロセスの非線形性や動特性を捉えることができますので、ぜひ参考にしてみてください!
本記事の内容
・特徴量エンジニアリングとは
・時間遅れ変数(ラグ特徴量)
・二乗項、交差項
・参考文献
特徴量エンジニアリングとは
まず、「特徴量エンジニアリング」について簡単にまとめました。
本記事では、下表の時間遅れ変数(ラグ特徴量)、二乗項、交差項の作成方法を紹介します。
| 手法 | 内容 | 例 |
| (1)特徴量の変換 | データのスケールや分布を変換する。 | スケーリング:正規化、標準化 非線形変換:対数変換、Box-Cox変換 次元削減:主成分分析、因子分析 |
| (2)特徴量の生成 | 特徴量同士の演算や組み合わせ、ドメイン知識の利用により、新たな特徴量を作成する。 | 二乗項、交差項、時間遅れ変数(ラグ特徴量)、移動平均 |
| (3)特徴量選択(変数選択) | データから不要な特徴量を除外することで、ノイズを減らして過学習を防ぐ。 | Filter法、Wrapper法、Enbedded法 |
サンプルデータの入手
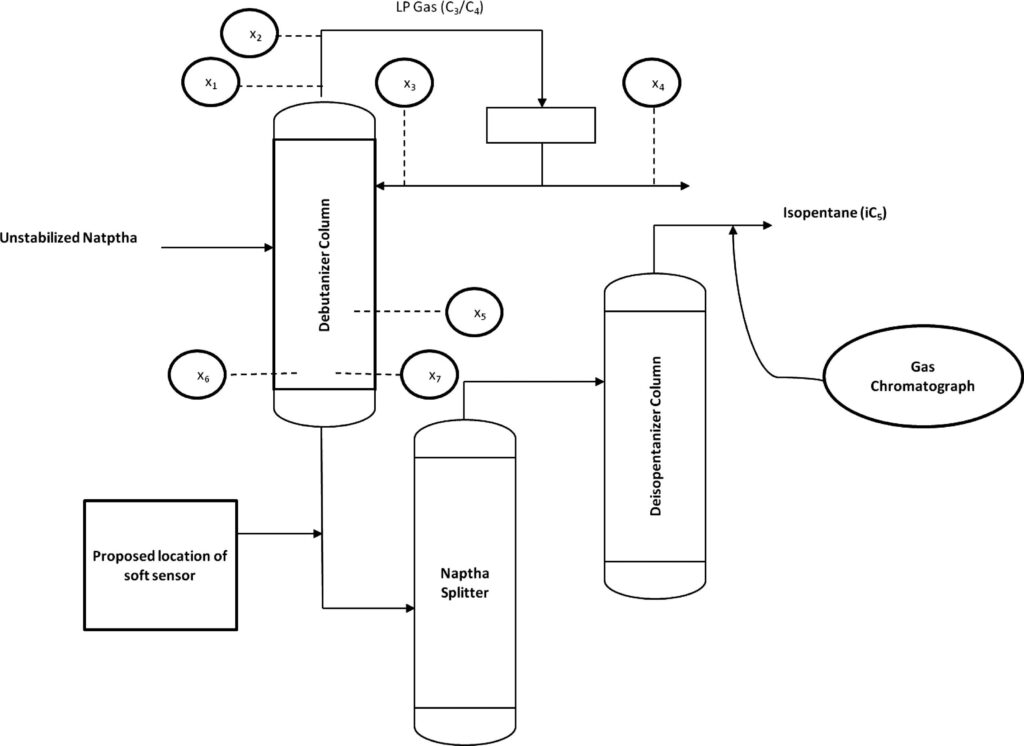
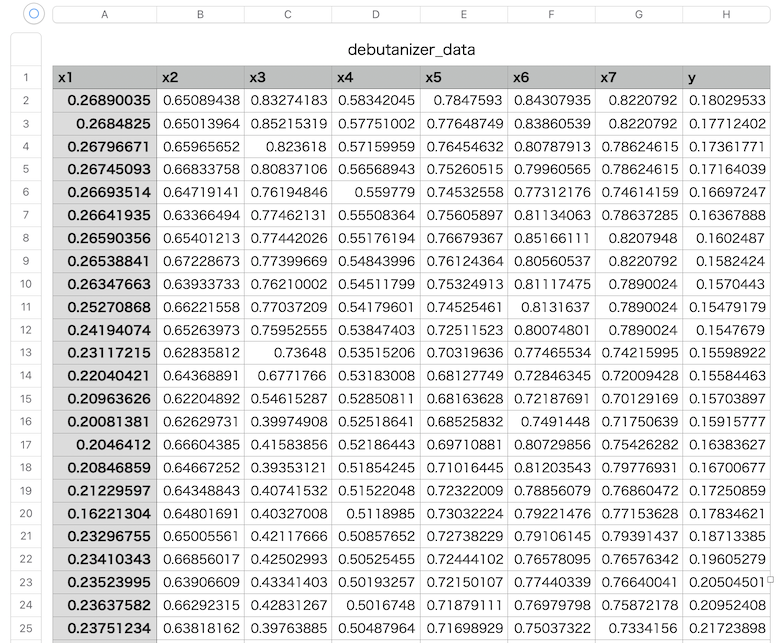
コチラのGitHubページで入手できる「debutanizer_data.csv」を利用します。
脱ブタン塔のプロセスデータであり、プロセスフローは上図の通りです。
説明変数がx1〜x7の7個で、目的変数がyの1個、サンプル数は2394個です。
| 変数名 | 詳細 | 日本語訳 |
|---|---|---|
| x1 | Top Temperature | 塔頂温度 |
| x2 | Top pressure | 塔頂圧力 |
| x3 | Reflux flow | 還流流量 |
| x4 | Flow to next process | 次プロセスへの流量 |
| x5 | 6th tray Temperature | 6段目温度 |
| x6 | Bottom Temperature1 | 塔底温度1 |
| x7 | Bottom Temperature2 | 塔底温度2 |
| y | Butane(C4) content in the debutanizer column bottom | 塔底におけるブタン含有量 |
データの読み込み
「debutanizer_data.csv」と同じフォルダに、「feature_engineering.ipynb」というファイルを作成しましょう。
下記のコードでライブラリのインポートと、データの読み込みを行います。
簡単な前処理として、目的変数yの測定時間を考慮し、5行だけずらしておきましょう。
import pandas as pd
#脱ブタン塔のプロセスデータを読み込む
df = pd.read_csv('debutanizer_data.csv')
# 目的変数の測定誤差を考慮
df['y'] = df['y'].shift(5)
#yがnanとなる期間のデータを削除
df = df.dropna()
時間遅れ変数(ラグ特徴量)の作成
製造プロセスでは、プロセスの後半で得られるデータ(例えば品質)を、プロセスの前半で得られるデータを用いて予測することがよくあります。
このような場合、プロセス前半で得られるデータの「過去値」を使用することで予測精度が向上することがあります。
そこで、プロセス前半で得られるデータの時間軸をズラした「新たな特徴量」を作成する必要があります。
この新たな特徴量のことを時間遅れ変数(ラグ特徴量)と呼びます。
下記のコードで時間遅れ変数(ラグ特徴量)を作成しましょう。
#説明変数と目的変数にわける
X = df.iloc[:, :-1]
y = df['y']
# 最大の遅延時間と遅延間隔(スパン)を設定
delay_max = 30
delay_span = 3
X_with_delays = X.copy()
# Xの各列について
for col in X.columns:
# 時間遅れ変数を追加
for delay in range(delay_span, delay_max + 1, delay_span):
col_name = f"{col}_delay_{delay}"
X_with_delays[col_name] = X[col].shift(delay)
# 目標データを追加
X_with_delays['y'] = y
# 欠損値がある行を削除
X_with_delays_fil = X_with_delays.dropna(how='any')
# データを保存
X_with_delays_fil.to_csv('time_delay_df.csv')
X_with_delays_fil.to_pickle('time_delay_df.pkl')
# 入力データと目標データに分割
X = X_with_delays_fil.iloc[:, :-1]
y = X_with_delays_fil['y']
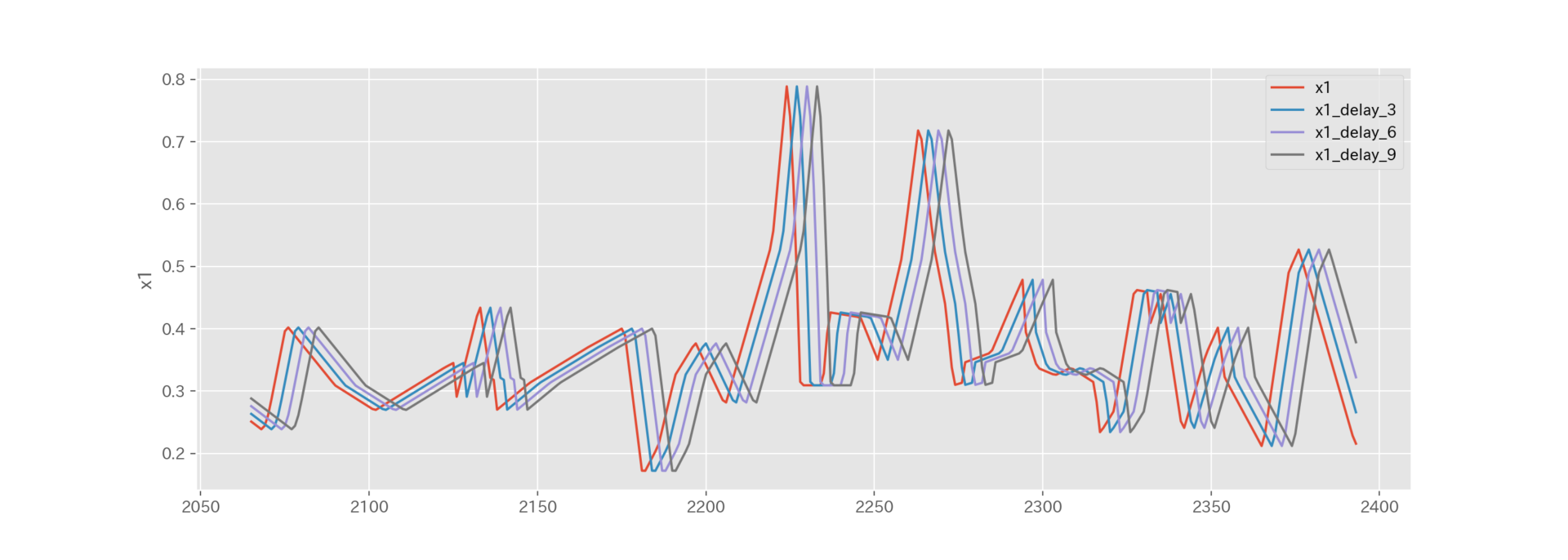
得られた時間遅れ変数をグラフで見てみましょう。
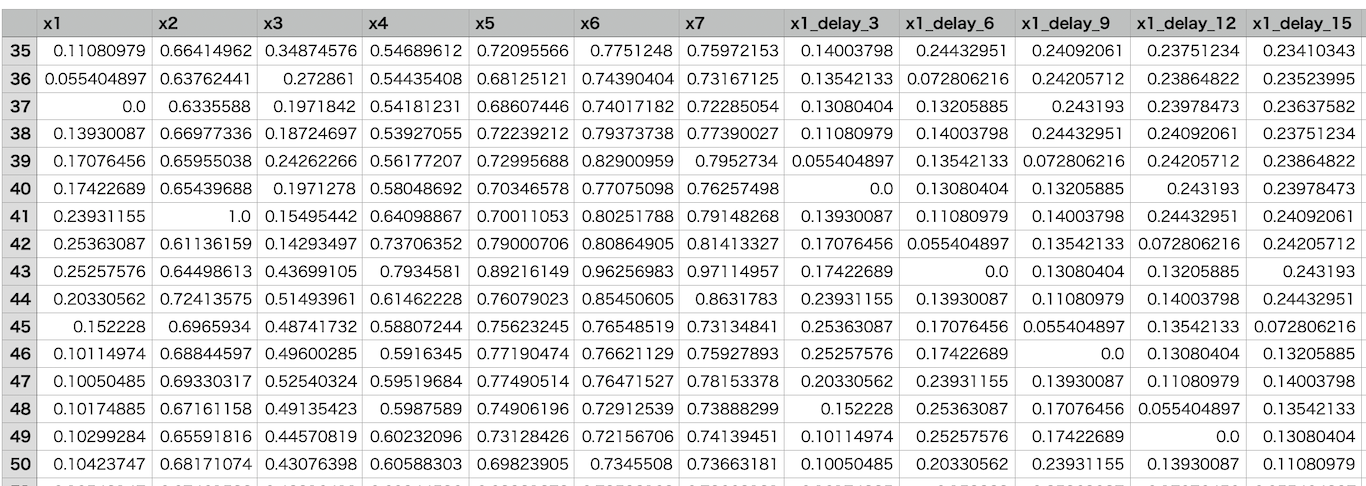
また、得られたデータセットの一部が下図の通りです。
x1の「0.0」のデータに着目すると、3行ずつ時間が遅れていることがわかります。
最大の遅延時間と遅延間隔(スパン)を目的に合わせて変更しながら使ってみてください。
二乗項、交差項の作成
続いて、二乗項と交差項を作成するコードを紹介します。
二乗項と交差項を用いることで、プロセスの非線形性を考慮することができます。
最小二乗法(OLS)や主成分回帰(PCR)、PLSのような線形回帰モデルを適用する際に、非線形性を考慮するために二乗項や交差項を作成する場合があります。
#説明変数と目的変数にわける
X = df.iloc[:, :-1]
y = df['y']
# 元の説明変数のデータセット
original_X = X.copy()
# 二乗項を追加
X_squared = X**2
X_squared.columns = [f"{col}^2" for col in X.columns]
X = pd.concat([X, X_squared], axis=1)
# 交差項を追加
for i, col1 in enumerate(original_X.columns):
print(i + 1, '/', original_X.shape[1])
for col2 in original_X.columns[i+1:]:
X[f"{col1}*{col2}"] = X[col1] * X[col2]
# データを保存
X.to_csv('squared_interaction_terms.csv')
X.to_pickle('squared_interaction_terms.pkl')
得られた二乗項や交差項をグラフで見てみましょう。
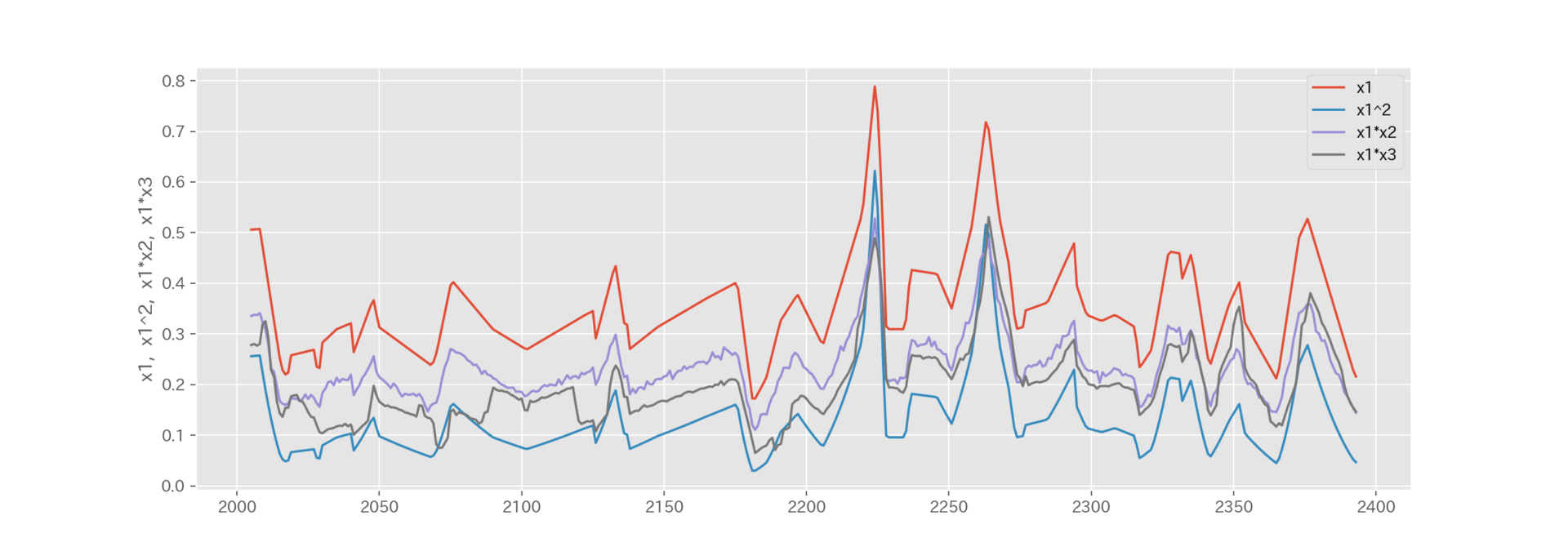
また、得られたデータセットの一部が下図の通りです。
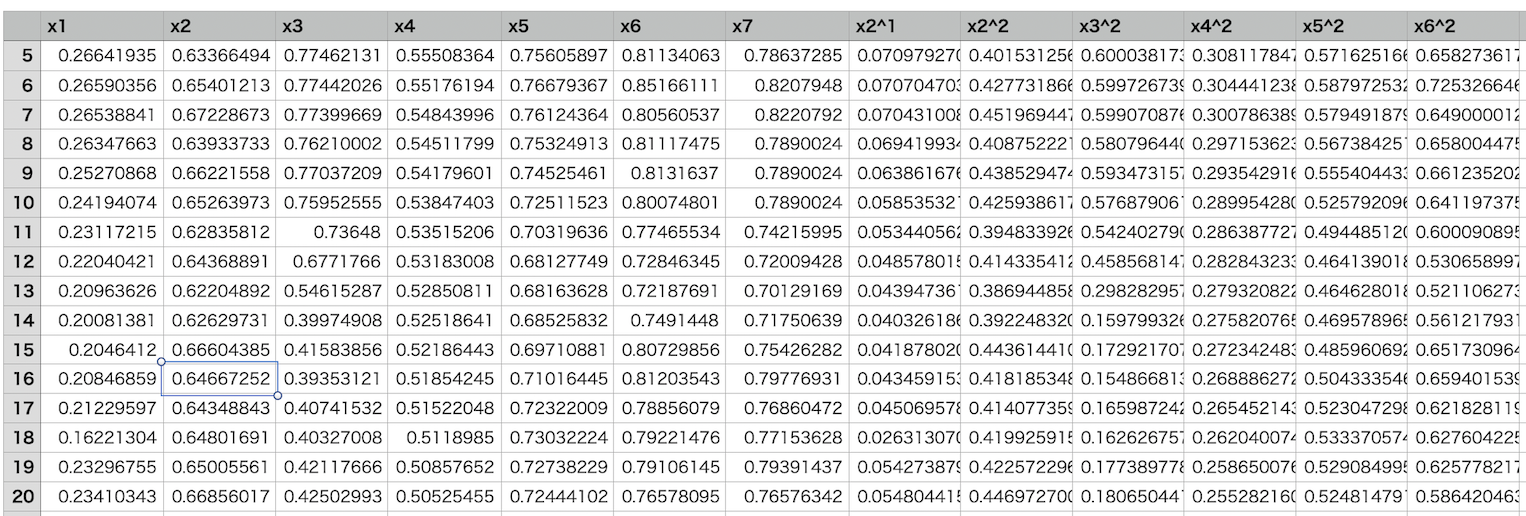
注意ポイント
下記の理由から二乗項・交差項をむやみに使うのはオススメしてません。
- 時間遅れ変数(ラグ特徴量)に比べると効果が小さいことが多い(経験的に)
- 無作為に作成した二乗項や交差項は解釈が難しい
- 原理原則から導出した数式や変換の方が効果が大きくなりやすい
参考文献
本記事は、こちらの書籍を参考に書きました。
著者のgithubにpythonコードがまとめてあり、いつも参考にさせてもらっています。
有益なブログ記事も書いているので、気になる方は覗いてみてください。